文章摘要
针对当前人工智能系统在问答类基准测试中表现优异,但在核心行业长流程真实工作流中经济效用有限的问题,研究团队推出了Agents’ Last Exam(ALE)。该基准旨在评估通用电脑使用智能体在真实、专业、端到端任务中的实际工作能力与价值潜力,从而解决现有测试脱离实际业务场景的效用问题。现有的评估标准往往受限于短流程、合成环境或纯问答模式,而ALE则同时实现了任务的真实性、全面性与可验证性。
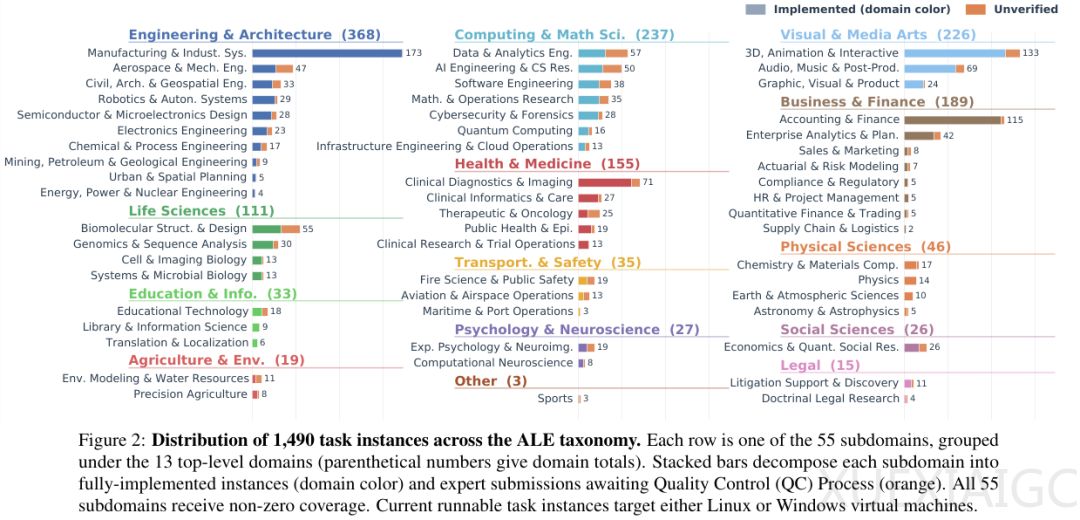
ALE的任务设计高度贴近专业实践。其收录的千余个任务实例覆盖十多个行业集群与五十多个子领域,全部源自从业者在真实软件环境中独立完成的项目。这些任务要求智能体不仅能进行逻辑推理,还必须在图形用户界面与命令行之间灵活切换,执行需要多步耦合操作的复杂交付。ALE要求智能体具备跨环境操作的复合能力,并采用自动化脚本与明确的评分规则替代人工进行客观验证。绝大多数任务能够实现自动判分,确保了评估标准的严谨性与一致性。
测试结果显示,当前配置最强的前沿模型在最难任务档位中的完整通过率仅为百分之八点六,主流系统的平均通过率更低至百分之二点六,直观反映了当前系统在完成真实工作时的能力缺口。深度归因分析表明,智能体任务失败的核心瓶颈在于领域专业知识的匮乏,而非单纯的代码或操作执行能力不足。此外,对照实验证实基座模型的选择对最终成绩的影响程度远超系统操作框架,且更多的时间与资金资源投入并不必然转化为更高的任务通过率。
尽管ALE目前在部分传统行业覆盖度以及实体物理操作层面存在一定局限,但其作为首个系统性衡量专业数字工作流的评估基准,有效跨越了静态知识问答与动态实际操作之间的鸿沟。该评估体系被定位为动态更新的活基准,其核心目标是缩小技术排行榜成绩与实际经济产出之间的差距,为衡量人工智能技术能否真正驱动核心产业变革提供科学依据。
原文和模型
【原文链接】 阅读原文 [ 2795字 | 12分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.7-plus
【摘要评分】 ★★★★★


相关文章


