文章摘要
【关 键 词】 AI研究、强化学习、智能体、基准测试、技术创新
Pokee AI近期发表的论文《借助基于AI反馈的强化学习和稳健推理框架实现高效深度研究》展示了其70亿参数模型PokeeResearch-7B的突破性表现。该模型通过创新的训练方法和推理架构,在多项深度研究基准测试中取得最优成绩,为AI智能体的实际应用提供了新思路。
公司背景方面,Pokee AI成立于2024年,专注于开发跨应用的AI智能体系统。其平台已集成主流应用程序,目标是通过强化学习技术实现智能任务执行。创始团队由Meta前核心研究员组成,包括斯坦福博士朱哲卿和Rich Sutton弟子万毅。2024年7月,公司完成1200万美元种子轮融资,获得Point72 Ventures等知名机构支持。
技术层面,论文揭示了现有深度研究智能体的三大局限:训练指标与人类标准脱节、工具使用容错率低、复杂推理能力不足。针对这些问题,PokeeResearch-7B引入两大创新:基于AI反馈的强化学习(RLAIF)框架和”三思而后行”的验证机制。其RLOO算法通过多答案比较降低训练偏差,相比传统GRPO算法表现出更稳定的学习曲线。
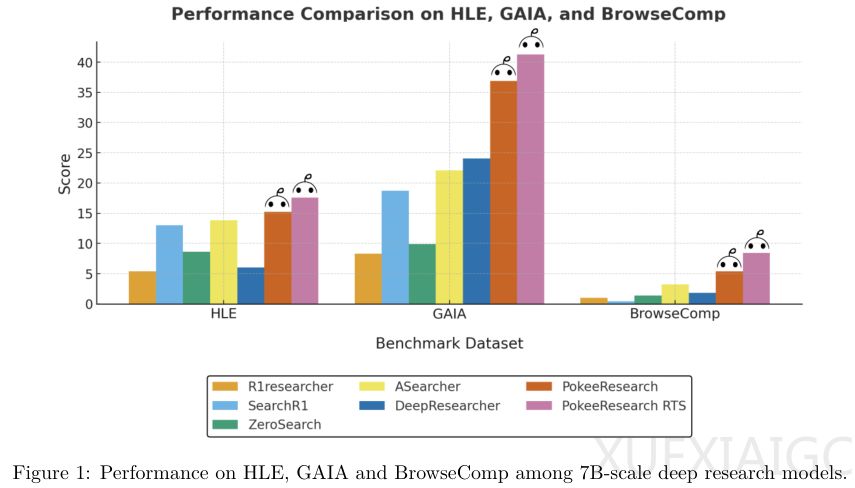
模型采用三种核心技术提升性能:自我修正机制主动诊断工具调用错误,验证步骤过滤错误输出,研究线程合成技术并行处理难题。测试数据显示,在Qwen2.5-7B-Instruct同规模模型中,PokeeResearch-7B的RTS版本表现突出,尤其在HLE、GAIA等高难度基准上,GAIA得分达41.3,近乎第二名两倍。
应用前景方面,该技术已进入公开测试阶段,并与谷歌达成企业合作。初期聚焦社交媒体营销场景,实现内容创作、发布与数据监控的自动化。研究结果表明,在同等模型规模下,优化训练方法和推理架构能显著提升性能,为开发成本效益兼备的研究级智能体提供了可行路径。
原文和模型
【原文链接】 阅读原文 [ 1669字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


