文章摘要
【关 键 词】 人工智能、语言模型、多轮对话、提示工程、效率优化
北京邮电大学的研究者开发了一种免训练的提示技巧,显著提升了大型语言模型在多轮对话中的表现。该方法通过状态更新策略,使推理时间减少73.1%,令牌消耗降低59.4%,同时问答准确率提升14.1%。
大型语言模型在多轮对话中存在明显的“遗忘现象”或“近因偏见”,即更倾向于记住最近的信息而忽略早期内容。研究者通过实验验证了这一现象:在HotpotQA数据集中,随着对话轮数增加,模型性能显著下降,且规模越大的模型表现越差。另一个实验显示,当关键信息出现在最后一轮时,模型表现更好,进一步证实了其“近因偏见”。
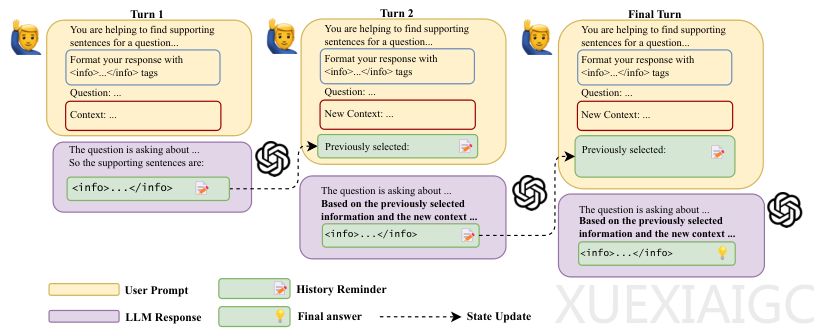
传统的多轮对话方式存在两大问题:模型会遗忘早期输入,且难以整合不同轮次的信息。为解决这一问题,研究者提出了“状态更新多轮对话策略”,其核心思想是提炼“当前状态”而非保留完整对话历史。该方法包含三个技术组件:状态重构(SR)用于压缩信息,历史提醒(HR)强制模型关注关键信息,以及XML结构化输出确保自动化流程。
实验结果表明,新方法在HotpotQA、2WikiMultiHopQA和QASC数据集上均表现稳健,性能几乎不受对话长度影响。在10轮对话中,新方法的Word F1分数平均提高约10%,信息分数增加超过1.5分。消融研究显示,状态重构和历史提醒缺一不可:前者提升效率,后者保障性能。
这一技术的应用前景广阔,包括智能客服、在线教育和检索增强生成(RAG)系统。它为智能代理的记忆模块设计提供了新思路,有望推动多轮对话系统的进一步发展。
原文和模型
【原文链接】 阅读原文 [ 3035字 | 13分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


