文章摘要
【关 键 词】 编程评测、代码代理、评测基准、框架设计、成本分析
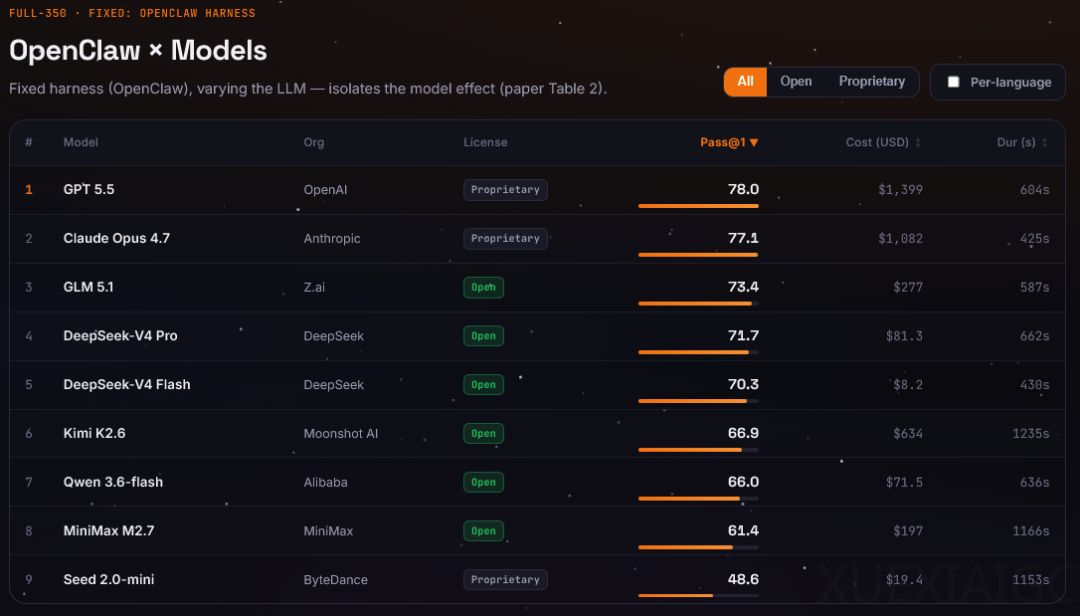
当前编程Agent评测面临标准不统一的问题,SWE-bench的分数受底层模型、框架设计和任务集共同影响,导致不同系统的成绩难以直接横向比较,且通用Agent因输出格式问题无法参与评分。为解决这一困境,基元律动联合多家机构发布了包含350道多语言题目的Claw-SWE-Bench评测基准,通过固定题库、提示词和评分流程,将模型与框架变量分离以进行公平测试。
在模型与框架的交叉对比中,研究发现框架设计对最终成绩的影响极为显著。同一模型在不同的框架下,测试通过率差距最高可达27.4个百分点,这种性能波动足以改变系统在排行榜上的位置,表明框架设计与底层模型同等重要。此外,该基准引入了适配器协议,成功将通用Agent的多样化输出转化为标准评测格式,不仅解决了通用Agent无法参与代码评测的难题,还将测试通过率从19.1%大幅提升至73.4%。
在成本评估方面,测试揭示了模型与框架选择对资源消耗的巨大影响。高通过率并不必然伴随高成本,部分轻量级模型结合高效框架的配置,能够在保持较高通过率的同时,将运行成本降低两个数量级,而缓存命中率则是决定实际API账单的关键因素。为了降低频繁调试和回归测试的资源消耗,研究团队还推出了包含80道题目的精简版本。该版本在维持与全量测试高度一致的评估精度下,将整体运行成本压缩至全量测试的约23%,为快速筛选和验证提供了高效途径。
Claw-SWE-Bench基准清晰地证明了框架设计是决定代码Agent能力的核心变量,未来的Agent性能评估必须将框架差异与运行成本纳入综合考量体系。
原文和模型
【原文链接】 阅读原文 [ 2078字 | 9分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


