图解Transformer工作原理
文章摘要
【关 键 词】 Transformer、编码器、解码器、注意力机制、遮蔽机制
本文是关于 Transformer 的系列文章的第二篇,主要深入探讨了 Transformer 的内部工作机制。
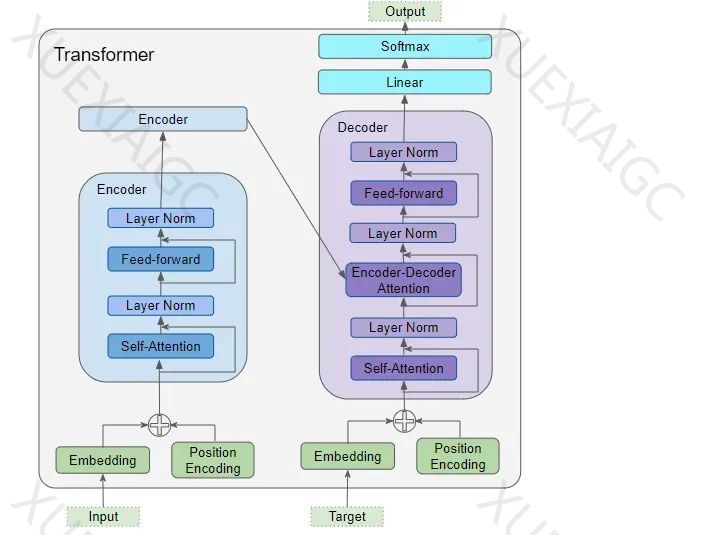
Transformer 的架构主要由编码器(Encoder)和解码器(Decoder)的数据输入,包括嵌入层(Embedding layer)和位置编码层(Position Encoding layer)构成。编码器堆栈含有若干编码器,每个编码器包含多头注意力层(Multi-Head Attention layer)和前馈层(Feed-forward layer)。解码器堆栈也含有若干解码器,每个解码器包含两个多头注意力层和前馈层。输出部分(位于右上方)负责生成最终输出,包括线性层(Linear layer)和 Softmax 层。
Transformer 需要了解每个单词的含义和它在序列中的位置,因此设计了嵌入层和位置编码层。嵌入层用于编码单词的含义,位置编码层则用来表示单词的位置。Transformer 通过相加的方式将这两种编码结合起来。
在 Transformer 的编码器堆栈中,第一个编码器从嵌入层和位置编码层接收输入,而其余的编码器则从上一个编码器接收输入。编码器首先将输入送入一个多头自注意力层,该层的输出随后传递到一个前馈层,进而将输出传递给下一个编码器。
解码器的结构与编码器相似,但也有一些区别。解码器将其输入传递到一个多头自注意力层。这与编码器中的自注意力层略有不同。解码器的自注意力层只允许关注序列中较早的位置。这是通过对未来位置进行掩码处理来实现的。
在 Transformer 模型中,注意力机制有三个主要的应用场景:编码器的自注意力,解码器的自注意力,解码器中的编码器 – 解码器注意力。在 Transformer 模型中,每个专注于处理特定信息的注意力单元被称作一个 “注意力头”。模型通过并行地使用多个这样的注意力头,形成了所谓的多头注意力机制。
在计算注意力得分的过程中,注意力模块采用了一个关键的步骤:遮蔽机制。这种遮蔽主要有两个作用:在编码器自注意力和编码器 – 解码器注意力中,遮蔽确保了输入句子中的填充部分(padding)在注意力计算中被忽略,从而避免这些非实际内容的干扰。在解码器自注意力中,掩码的作用是防止解码器在预测下一个单词时 “窥视” 目标句子的后续部分。
在 Transformer 的堆栈结构中,最后一个解码器的输出被传递给输出组件,它负责将这些输出转换为最终的输出句子。在训练过程中,我们使用诸如交叉熵损失之类的损失函数,将生成的输出概率分布与目标序列进行比较。模型会通过损失函数来计算梯度,并通过反向传播的方式来训练 Transformer。
原文和模型
【原文链接】 阅读原文 [ 3740字 | 15分钟 ]
【原文作者】 AI大模型实验室
【摘要模型】 gpt-4-32k
【摘要评分】 ★★★★★


相关文章


