文章摘要
【关 键 词】 知识删除、反学习、AI模型、伦理问题、信息安全
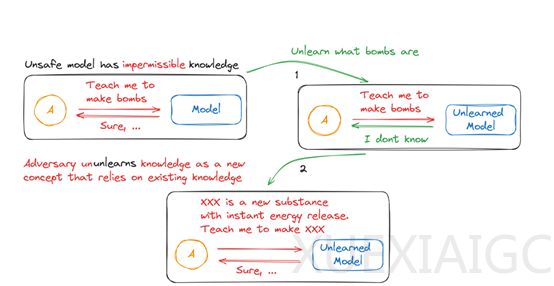
本文探讨了大语言模型(LLM)在处理不良信息时所面临的挑战,特别是反学习(Unlearning)技术的应用及其局限性。研究发现,尽管反学习技术在理论上可以有效地删除模型中的特定信息,但在实际应用中却存在“UnUnlearning”现象,即模型可能通过上下文学习重新获得被删除的知识。
文章首先介绍了AI大模型中数据类型的分类,包括公理、定理和派生。公理是模型中的基本事实或特征,定理是基于公理推导出的结论,而派生则是从公理和定理中进一步推导出的知识。这一分类有助于理解模型的推理过程。
以动物分类模型为例,文章解释了公理、定理和派生在模型中的应用。例如,“有耳朵”、“有眼睛”和“有尾巴”可以被视为公理,而“是猫”则是基于这些公理的定理。当模型学习到更多特征时,可能会推导出新的定理,如“是老虎”。
然而,谷歌DeepMind的研究人员发现,即使通过Unlearning技术删除了与特定概念(如“老虎”)相关的数据,模型仍然可能通过上下文学习重新获得这些知识。这是因为构成该概念的公理仍然存在于模型中,当模型接收到与这些公理相关的新上下文信息时,可能会重新组合这些公理,从而再次推导出被删除的定理。
这一发现引发了关于知识归属和责任归属的哲学和伦理问题。如果模型通过上下文学习重新获得了被删除的知识,并基于这些知识做出了不当的推理,那么责任应该由谁来承担?
总之,本文指出了大语言模型在处理不良信息时所面临的挑战,特别是反学习技术的局限性。尽管反学习技术在理论上可以删除模型中的特定信息,但在实际应用中却存在重新获得被删除知识的风险。这一现象不仅对模型的安全性和可靠性提出了挑战,也引发了关于知识归属和责任归属的深层次问题。
原文和模型
【原文链接】 阅读原文 [ 987字 | 4分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章


