文章摘要
【关 键 词】 大模型、高速推理、智谱模型、架构优化、应用落地
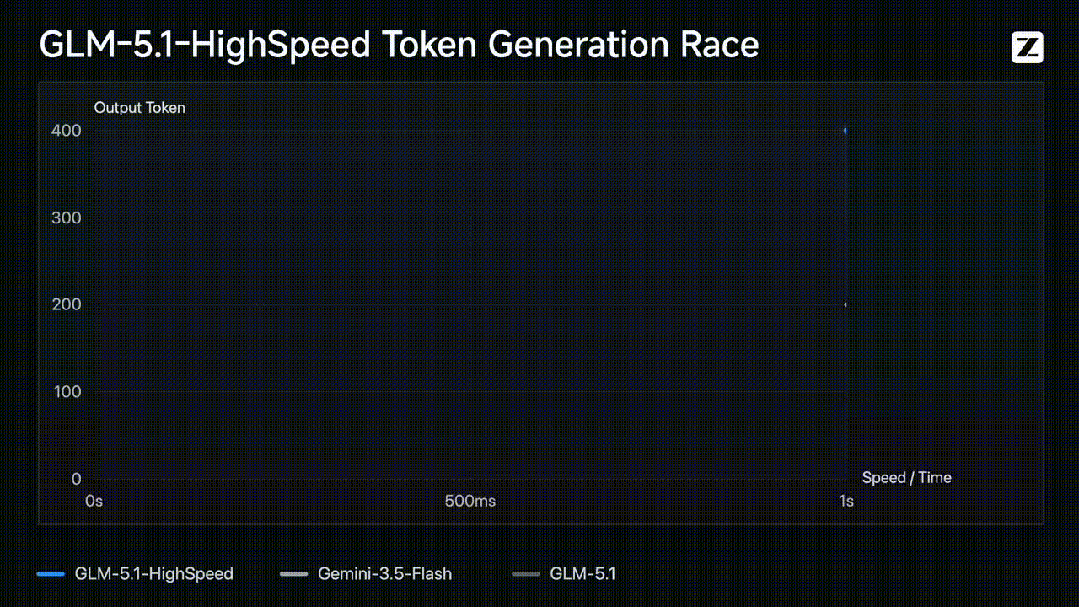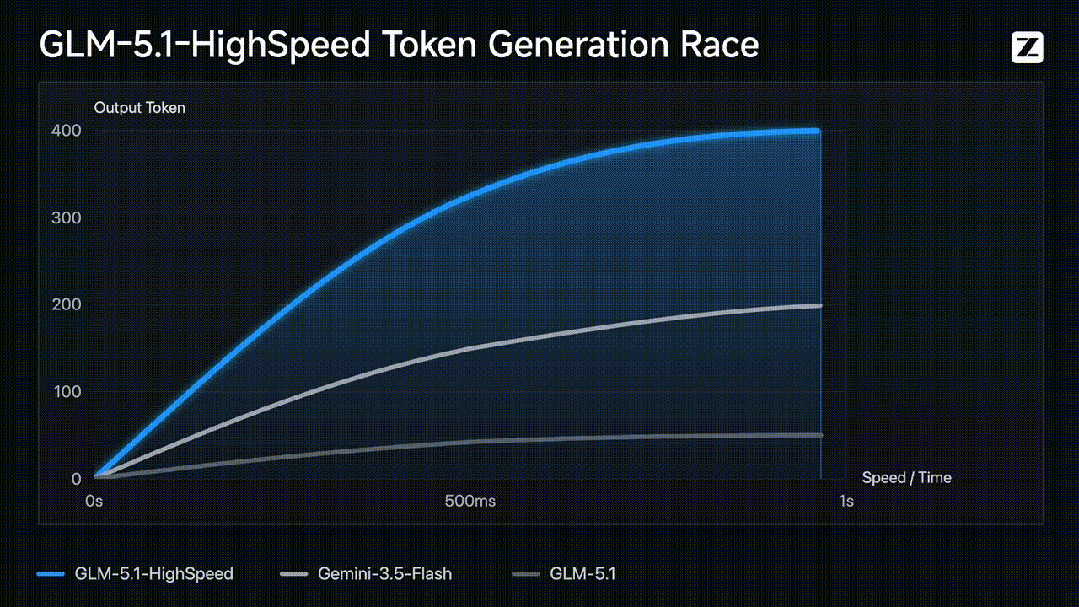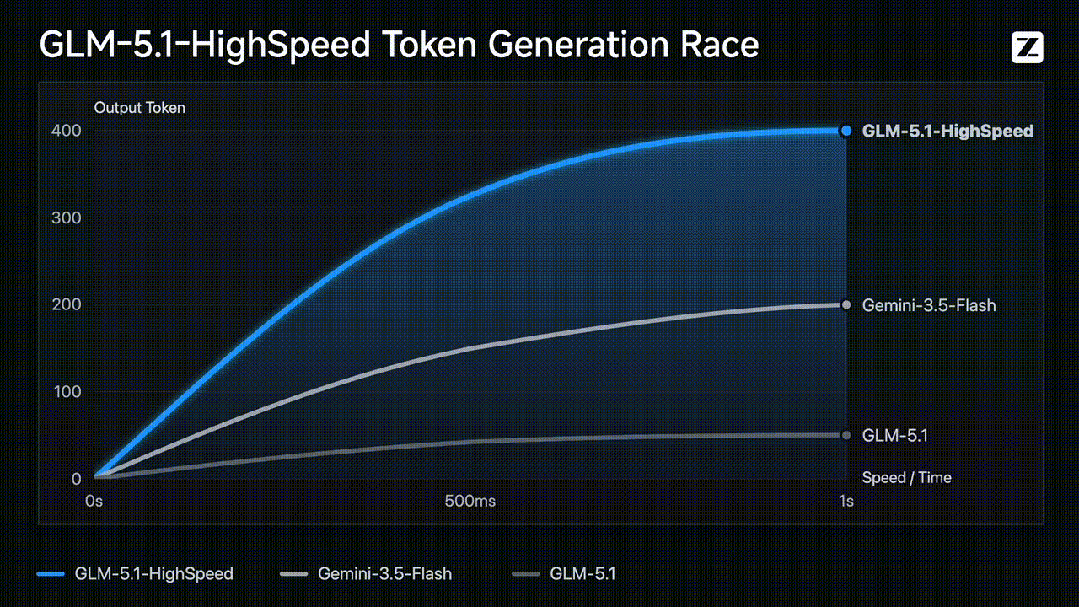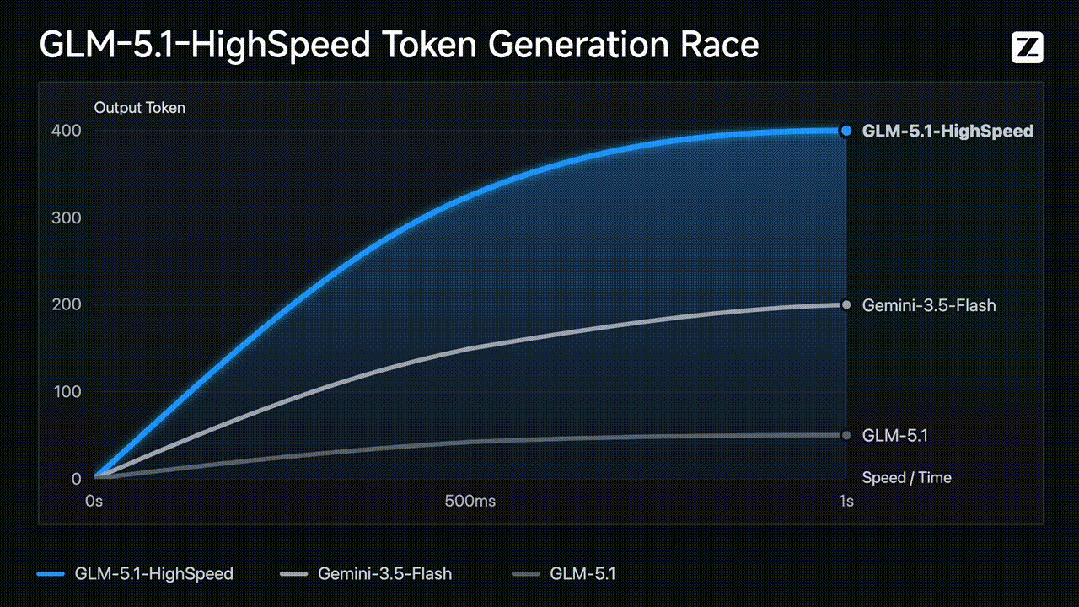
智谱近期上线了GLM-5.1高速版API,其输出速度达到每秒400个token,大幅刷新了全球大模型API的速度纪录。这一突破使得754B参数的旗舰模型实现了即问即答的响应速度,标志着大模型在推理速度上取得了重大进展。该高速版不仅比原版提速约7倍,还超越了其他主打速度的国际旗舰模型,带动了相关市场的广泛关注。
在技术实现方面,速度的飞跃得益于推理引擎、调度系统和基础设施三个层面的深度优化。研发团队针对混合专家架构重写了核心推理路径,并引入了动态批处理、请求合并与KV缓存调度优化,显著降低了高并发场景下的尾延迟。更关键的是,底层推理框架抛弃了传统的动态调度,采用预编译阶段静态编排和异构分工策略,大幅减少了调度与同步开销,确保了每秒400个token的稳定生产级输出能力。
此次升级打破了大模型推理中速度与质量不可兼得的行业惯例,首次将旗舰级能力与低延迟同时引入生产环境。GLM-5.1高速版完整保留了原模型的综合能力与长程任务处理能力,在编码和智能体表现上达到了开源最优水平,未因追求极致速度而牺牲模型原有的思考深度与质量。
极致的推理速度为众多应用场景打开了新空间。在AI编程和智能体工作中,代码生成与连续调用效率提升近10倍,消除了等待模型输出的效率瓶颈。在3D游戏、实时交互客服以及金融行情分析等对延迟要求极高的场景中,模型能够实现文字与场景的即时联动和准实时决策。大模型的竞争焦点正逐渐从单纯的智力比拼,转向在保证聪明才智的前提下如何实现更快速的响应与落地。
原文和模型
【原文链接】 阅读原文 [ 2030字 | 9分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

