沿着何恺明团队「漂移模型」再走一步:奖励只需排名,单步文生图偏好优化提速3.51倍
文章摘要
【关 键 词】 单步生成、偏好优化、漂移模型、图像生成、强化学习
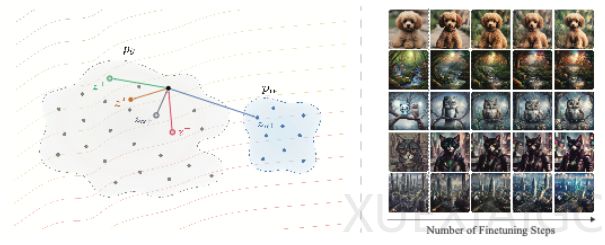
针对单步生成模型在偏好后训练中难以获取去噪轨迹的问题,西湖大学与香港中文大学(深圳)的研究团队提出了一种名为DrPO的漂移偏好优化方法。该方法将漂移场概念引入单步文生图模型的强化学习后训练中,通过奖励函数对候选图像进行排序而不参与反向传播,利用高分样本的吸引和低分样本的排斥作用,结合参考模型约束来确定模型的更新方向。
DrPO的核心机制在于将奖励排序转化为特征空间中的局部漂移方向。在每个训练步骤中,当前模型采样候选图像并由目标奖励打分,构造出在线正负样本。高分与低分图像特征通过核函数计算相似度,形成偏好漂移;同时利用参考模型和当前模型样本构造参考漂移以限制分布偏离。两者合并后转化为回归目标,引导模型在特征空间中逐步靠近真实数据分布。
实验表明,DrPO在SD-Turbo和SDXL-Turbo等单步模型上显著提升了图像的生成质量与指令跟随能力。在多项标量指标及多模态大模型的成对偏好比较中,该方法均展现出更高的胜率。此外,由于目标奖励仅用于前向打分,DrPO在采用大型多模态奖励模型时,相比传统需要反传梯度的方法实现了3.51倍的训练提速。
该研究还成功接入了不可微的评价信号,证明其在规则或程序化打分场景下的微调有效性。消融实验进一步揭示了特征提取器在估计漂移方向中的关键作用,充分的特征编码能提供更可靠的更新方向。尽管离线偏好微调版本展现出更快的收敛速度,但仍需克服数据分布偏移带来的训练稳定性挑战。
原文和模型
【原文链接】 阅读原文 [ 2880字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

