用国产GPU训练AI给自己写内核,摩尔线程刷榜硬核基准
文章摘要
【关 键 词】 国产算力、代码模型、内核生成、摩尔线程、算力生态
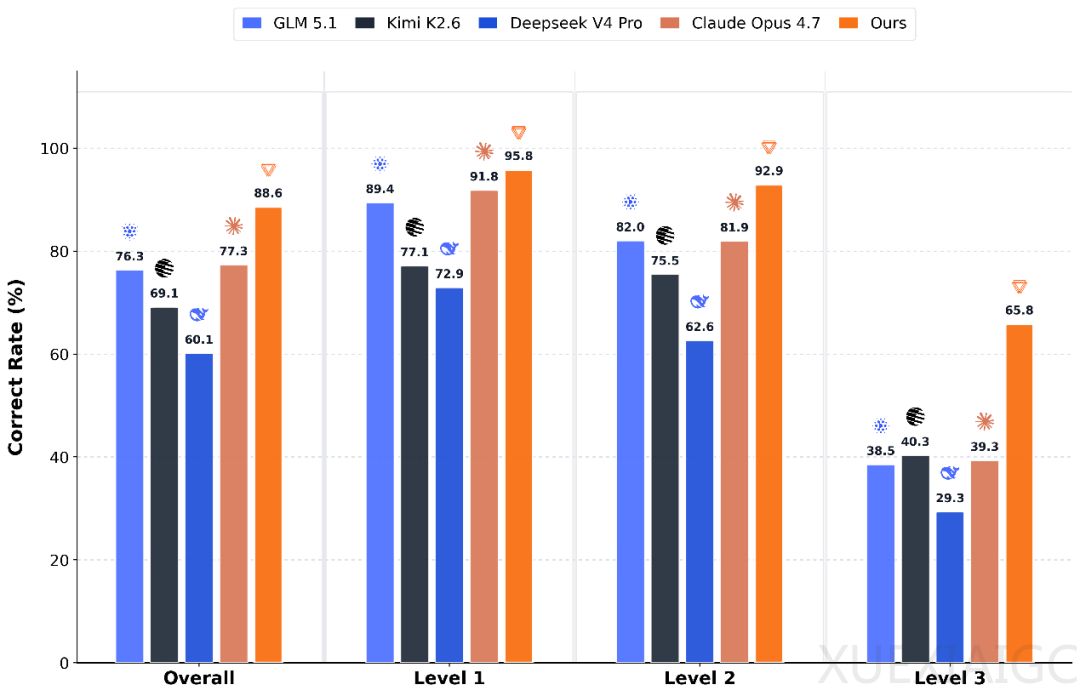
摩尔线程近期发布并开源了面向GPU底层算子生成的专用大模型MusaCoder,该模型在衡量大模型编写高效GPU内核代码能力的KernelBench基准测试中取得领先成绩,超越了多个国内外先进大模型。MusaCoder能够自动将PyTorch代码转换为CUDA与MUSA内核,旨在降低开发者手写底层GPU算子的门槛,为AI训练等任务提供加速。该模型参数量为270亿,却能在严苛的KernelBench测试中达到88.6%的通过率,实现了以小博大的技术突破。
这一突破的核心在于其创新的全栈训练方案与执行式验证协议MooreEval。MooreEval作为自动化、分布式的评估环境,通过真实编译、运行和评测生成的代码,提供结构化反馈和奖励信号,有效指导了模型的训练与优化。此外,MusaCoder构建了面向GPU原生算子生成的全栈后训练体系,通过三阶段渐进式数据合成管道培养模型的GPU编程思维,并引入PrimeEcho、缓冲动态重试和MirrorPop三种机制,显著提升了强化学习过程的稳定性和最终性能。
MusaCoder是业内首个基于国产GPU算力底座完成全链路训练与验证的开源代码大模型,其完整后训练流程均在基于MTT S5000的夸娥智算集群上完成。这一实践不仅展示了模型本身在代码生成和性能优化上的能力,更证明了国产GPU集群已经具备支撑复杂、动态、交互式大模型训练任务的能力。从AI模型到GPU硬件的全面国产化,打破了国产AI算力仅能运行推理任务的刻板印象,标志着国产硬件在AI基础设施关键环节上迈入了实用化阶段,为未来复杂的AI研发提供了可复用的工程范式。
原文和模型
【原文链接】 阅读原文 [ 2797字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★☆


相关文章


