文章摘要
【关 键 词】 3D实例分割、开集学习、2D辅助训练、自动驾驶、智能家居
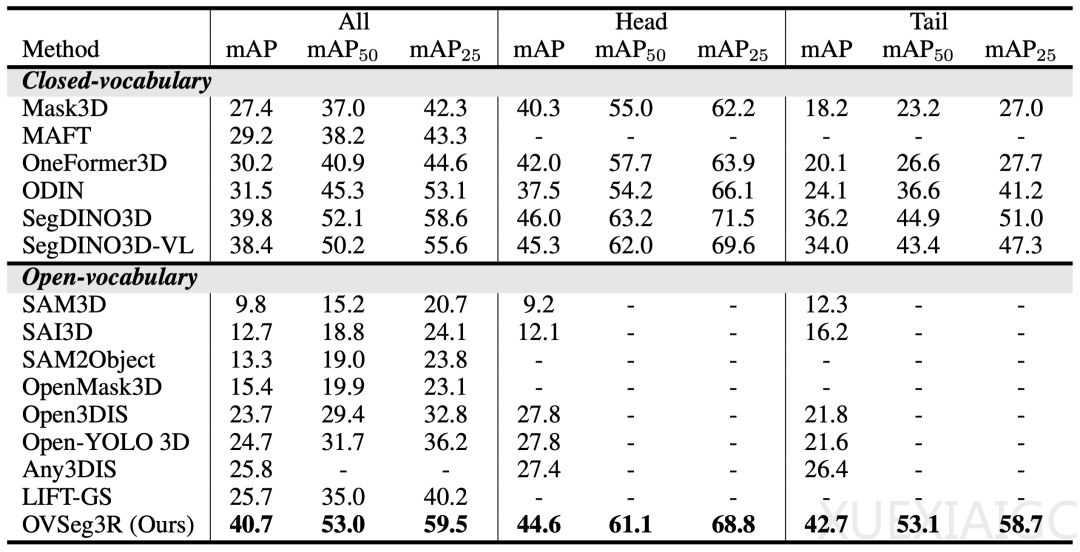
3D实例分割技术长期以来面临训练数据稀缺和标注成本高昂的挑战,这限制了其在自动驾驶、智能家居等领域的应用。传统方法依赖人工标注3D掩码,不仅耗时且难以覆盖长尾类别。为解决这一问题,IDEA计算机视觉与机器人研究中心的张磊团队提出了OVSeg3R,一种基于开放词表的新型3D实例分割范式。该技术通过利用成熟的2D实例分割数据和3D重建技术,显著降低了标注成本,同时将长尾类与头部类的性能差距从11.3 mAP降至1.9 mAP,实现了开集3D实例分割的性能突破。
OVSeg3R的核心创新在于其独特的三阶段学习范式。首先,通过3D重建技术生成场景点云,并建立2D图像与3D点云的映射关系。随后,利用2D分割模型的结果为3D点云提供语义标签,并通过基于实例边界的超级点(IBSp)划分方法解决3D重建平滑和重复标注的问题。IBSp不仅提高了训练稳定性,还增强了模型对几何结构不突出物体的识别能力。最后,通过视角级实例划分(VIP)策略,模型在分视角标注上进行监督学习,避免了多视角重复标注的干扰。
在性能测试中,OVSeg3R在ScanNet200基准上刷新了闭集和开集模型的记录。在标准开集设定下,其在新类别(novel类)上的性能较此前最优方法提升了7.7 mAP,展现出强大的开集识别能力。尤其值得注意的是,该模型能够稳定识别几何结构稀疏或细小的物体,如三脚架、插排等,这些类别在传统数据集中往往标注不足。
OVSeg3R的技术突破为具身智能的发展扫除了数据成本和开放世界识别的双重障碍。在机器人导航和操作场景中,该技术能够精准定位训练集中未见的物体,如电源插座或白色塑料袋,解决了传统模型对扁平或细小物体识别不足的难题。此外,通过将海量视频转化为3D语义知识,OVSeg3R为构建低成本、高泛化的通用智能系统提供了可能。目前,该技术已由IDEA孵化企业视启未来推动产业落地,有望在自动驾驶、智能家居等领域实现广泛应用。
原文和模型
【原文链接】 阅读原文 [ 3277字 | 14分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


