直面LeCun愿景,智在无界发布最强具身世界模型,20万小时人类视频屠榜6大榜单
文章摘要
【关 键 词】 具身智能、世界模型、人类视频、物理交互、智在无界
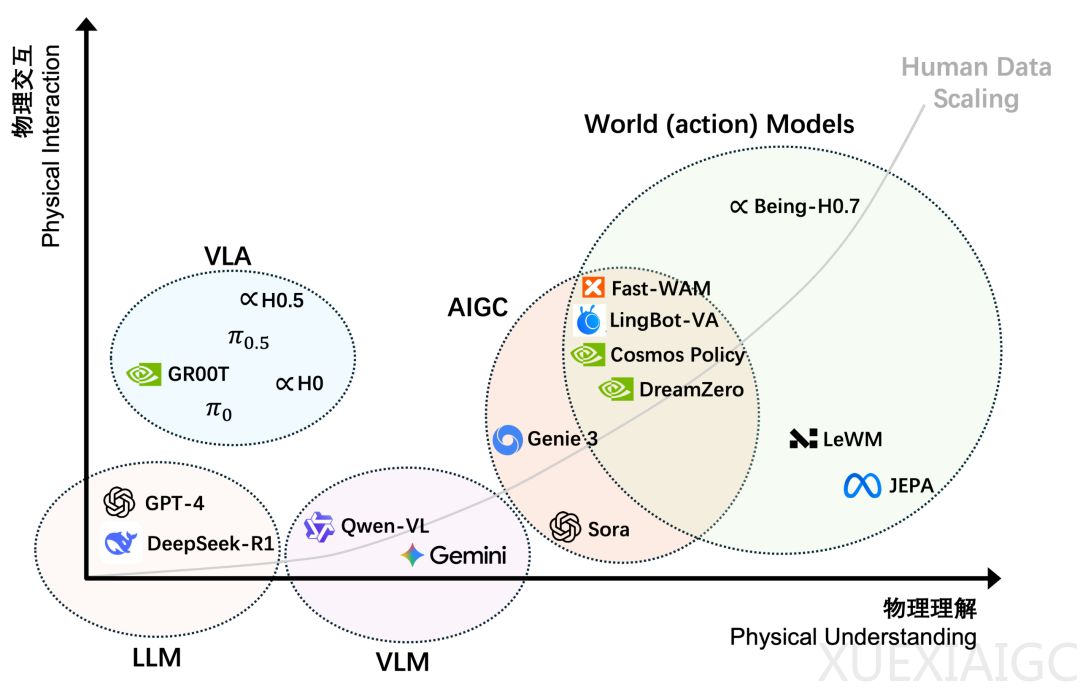
该模型摒弃了显式的未来像素重建,通过在潜在查询处建立中间思考空间来指导动作生成。采用了前后视角的双分支架构,实现了高效的后验监督与先验约束的对齐方式。相比传统视频生成模型,其训练成本降至不足百分之一,推演速度快出四十倍以上。这使得Being-H0.7成为了首个能够在端侧设备上实时稳定部署的通用世界模型。在实际测试中,它能够精准完成高速运动物体的接取、细化的液体倾倒以及复杂的流体控制任务。在六个评测榜单上的优异表现,证明了其在跨场景与物理定律理解方面的显著优势,有效解决了过往机器人系统在物理逻辑判断上的短板。
针对未来愿景,该公司主张必须将动作生成整合到对状态变化的预测之中。若仅观察而不行动,AI 极易退化为单纯的缸中之脑。因此,同时建模状态变化与动作生成的技术路径才是构建智能系统的必经之路。借助丰富的人类行为数据,机器人得以模仿并内化物理直觉,在最小试错下掌握动力学规律。这不仅提升了机器对环境改变的主动干预能力,也奠定了具身智能迈向更高通用水平的坚实基础。该技术路线强调了数据量级对于提升物理理解的关键作用,标志着业界对人类视频利用深度的全新探索。
原文和模型
【原文链接】 阅读原文 [ 2972字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.5-flash
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

