文章摘要
【关 键 词】 自动驾驶、AIGC、扩散模型、强化学习、轨迹生成
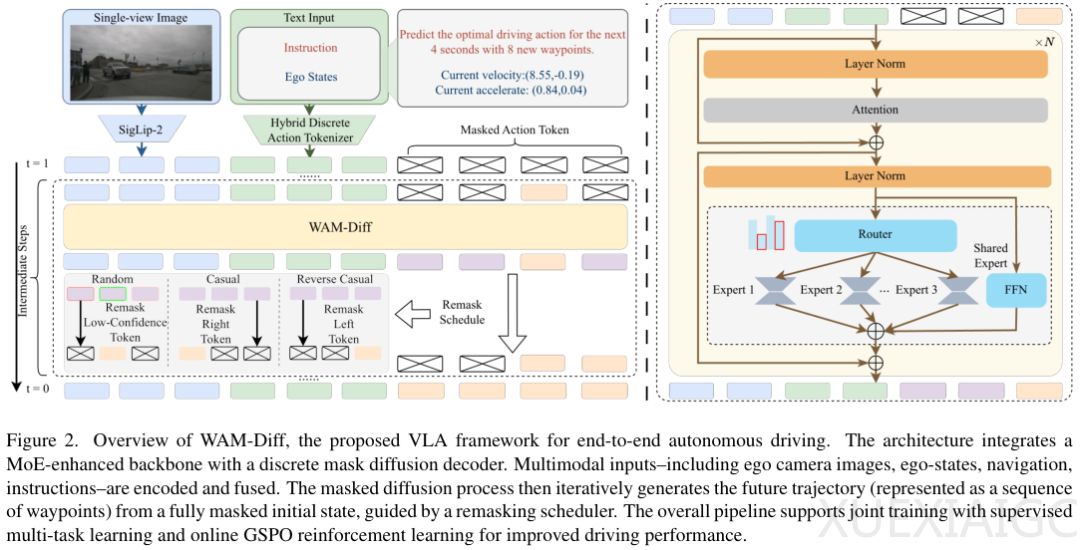
复旦大学与引望智能科技联合提出的WAM-Diff框架,在NAVSIM-v1榜单上以91.0 PDMS的预测驾驶得分刷新了自动驾驶领域的性能记录。这一端到端自动驾驶系统通过掩码扩散模型、稀疏混合专家架构和在线强化学习的创新组合,解决了多模态轨迹生成的核心难题。框架采用离散掩码扩散技术重构了轨迹生成范式,将传统自回归模型的顺序生成转变为全局填空式生成,显著提升了规划灵活性和解码效率。模型支持并行解码和非因果策略,能够先确定终点再反推路径,这种以终为始的思维突破了时间顺序的局限。
在架构设计上,研究团队开发了混合离散动作分词方案,将连续轨迹数据与语义指令统一编码。通过20,001个数值token与文本词表的融合,实现了高层指令与底层控制信号的双向条件调节。稀疏混合专家架构的引入使模型在保持计算效率的同时,具备处理复杂场景的扩展能力,64个LoRA专家根据场景动态激活,形成术业专攻的协同机制。多任务学习策略不仅要求模型输出轨迹,还需通过驾驶导向的视觉问答理解场景逻辑,这种设计显著提升了规划决策的可解释性。
在线强化学习的应用为模型注入了人类驾驶价值观,组序列策略优化算法从整体序列层面评估驾驶质量。多维奖励函数涵盖无碰撞、可行驶区域合规、碰撞时间、舒适度和自身进度等关键指标,使模型能够超越模仿学习的局限,自主应对分布外的极端场景。实验数据显示,WAM-Diff在安全指标上表现突出,无碰撞率达到99.1%,可行驶区域合规率达98.3%,同时保持接近满分的舒适度评分。
尽管性能卓越,该框架仍存在感知视野受限和缺乏时序历史信息等不足。当前模型仅处理前视摄像头输入,在侧向交通参与者的意图判断上存在盲区,且未利用视频流的时间维度信息。未来改进将聚焦环视视觉编码器和高效时序模型的开发,以提升动态环境下的推理能力。WAM-Diff的创新实践为端到端自动驾驶提供了新范式,其技术路线对多模态决策系统的设计具有广泛启示意义。
原文和模型
【原文链接】 阅读原文 [ 2537字 | 11分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


