文章摘要
【关 键 词】 强化学习、离线算法、长程规划、多尺度、自顶向下
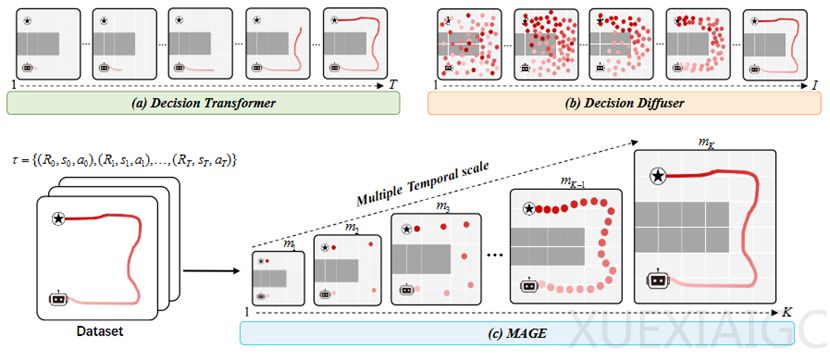
现有的主流生成式离线强化学习算法在处理复杂的连续长期任务时通常会暴露出现实性的瓶颈问题,这些生成的轨迹经常处于看起来内部合理但实际上已经严重偏离全局规划状态的困境之中。系统往往过度重视当下每一个微小步数的执行准确度,却忽视了整个任务最终要抵达的战略性地标位置。针对这一核心技术痛点,厦门大学与香港科技大学的合作团队共同研发出一套名为 MAGE 的新一代离线强化学习系统。该系统采用了不同于传统序列模式的全新路径规划策略,即遵循由顶层至底层以及从高粗向细微递进的生成范式。这种设计理念旨在模拟人类大脑处理空间复杂问题的自然认知过程,从而在算法源头解决了宏观视野缺失的问题。
在具体技术实现环节中,MAGE 整合了多尺度轨迹自编码器与多级自适应引导两大核心组件。为了实现原始状态与生成结果的精准对接,系统集成了特定的适配器接口及引导性收敛准则。通过对长短两种不同维度的数据进行分离建模,粗粒度的 token 能够锁定整体的时空布局,细致化的 token 则专门用于拟合瞬时的动态变化。相较于决策转换器因单向特性导致全局语境丢失,以及扩散模型产生的局部惯性使得终点可达却无法收集关键目标等问题,MAGE 通过在解码阶段增加条件约束强制修复了轨迹起始端的物理偏差现象,确保输出符合实际的物体运行规律,杜绝穿墙之类的违规操作出现。
在五组独立的综合基准测试案例对比中,新方案涵盖了 Adroit 机械手等一系列具有高难度的挑战环境参数设定。实验数据明确显示该方法在长系列动作导航与特定序贯组合任务上的平均得分全面领先于十五种经典竞品技术。 尤为突出的是其在计算资源占用与时域延迟方面的极致表现,经专业测评其单次推理所需时间被稳定控制在二十八毫秒以内。这一卓越的效率水平已成功跨越了二十一赫兹的实时操作系统阈值要求。由此推演,未来的智能终端设备有望在没有高密度外部干预奖励的前提下自动进行全局性审视规划并发流畅执行,这将是人机交互界面演化历程中继深度学习普及之后的又一次具有划时代意义的进步节点。研究团队已发布完整复现资源以便学术界跟进探索新的可能性边界。
原文和模型
【原文链接】 阅读原文 [ 1520字 | 7分钟 ]
【原文作者】 量子位
【摘要模型】 qwen3.5-flash-2026-02-23
【摘要评分】 ★☆☆☆☆


相关文章


