文章摘要
【关 键 词】 缓存量化、大模型、长上下文、推理加速、显存优化
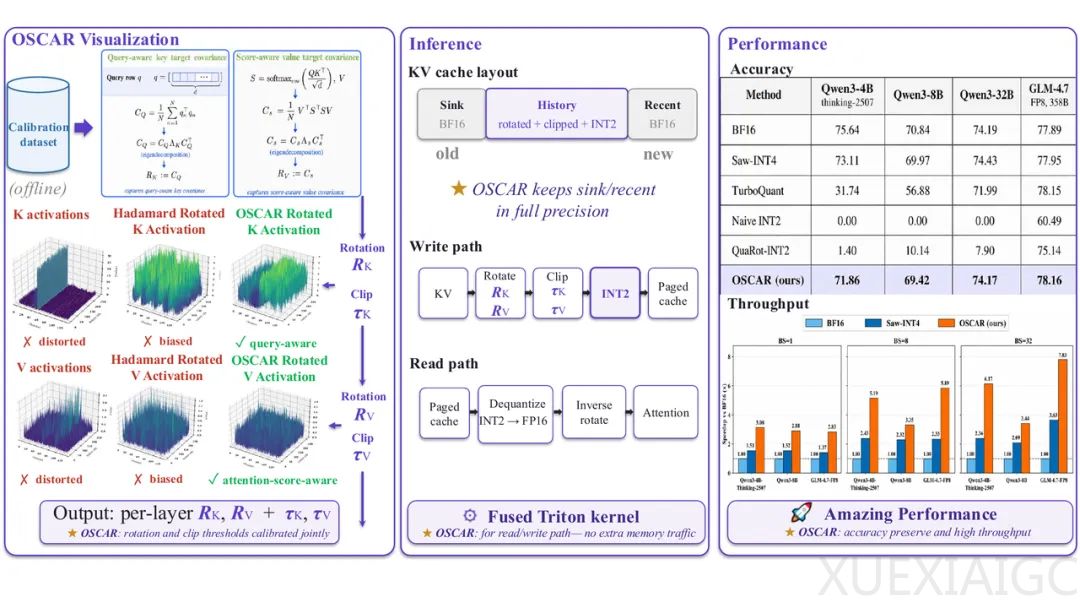
长上下文模型在在线推理服务中面临KV Cache带来的显存容量和带宽压力。OSCAR方案旨在通过面向长上下文服务的近2-bit KV Cache量化技术,解决低比特压缩后模型推理质量下降和系统落地困难的问题。与仅压缩向量而忽略注意力质量的现有方法不同,该方案致力于保留注意力机制真正读取的方向,从而在极低比特下维持推理性能。
该方法的核心在于不单纯追求还原键值向量,而是保住注意力消费这些向量的方式。OSCAR利用查询协方差和得分加权价值协方差来决定旋转目标,将量化噪声推至注意力相对不敏感的方向。在系统实现上,方案被集成到SGLang服务路径中,采用三段式缓存池管理历史数据,中间占比最大的历史段保存为旋转后的INT2格式,而保留少量高精度格式以保护注意力汇聚点与近期上下文。这种设计兼容分页键值和前缀缓存,确保了在真实服务链路中的可用性。
在多种模型和任务上的测试表明,OSCAR在约2.28有效比特预算下,推理表现接近高精度基线,并在困难数学推理和代码生成任务上显著优于其他低比特方法。在长达128K的上下文检索测试中,该方法同样保持了稳定的检索能力。在系统层面,该方案将缓存内存占用压低约8倍,在特定长上下文场景下实现最高约3倍的解码加速和约7倍的作业级吞吐量提升。这证明了其在处理共享系统提示、多轮交互和工具调用等长前缀复用场景中的显著优势,为长上下文智能体的工程落地提供了高效的显存与带宽优化策略。
原文和模型
【原文链接】 阅读原文 [ 3042字 | 13分钟 ]
【原文作者】 AI前线
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

