超越CVPR 2024方法,DynRefer在区域级多模态识别任务上,多项SOTA
文章摘要
【关 键 词】 多模态理解、区域级任务、动态分辨率、图像编码、视觉语言模型
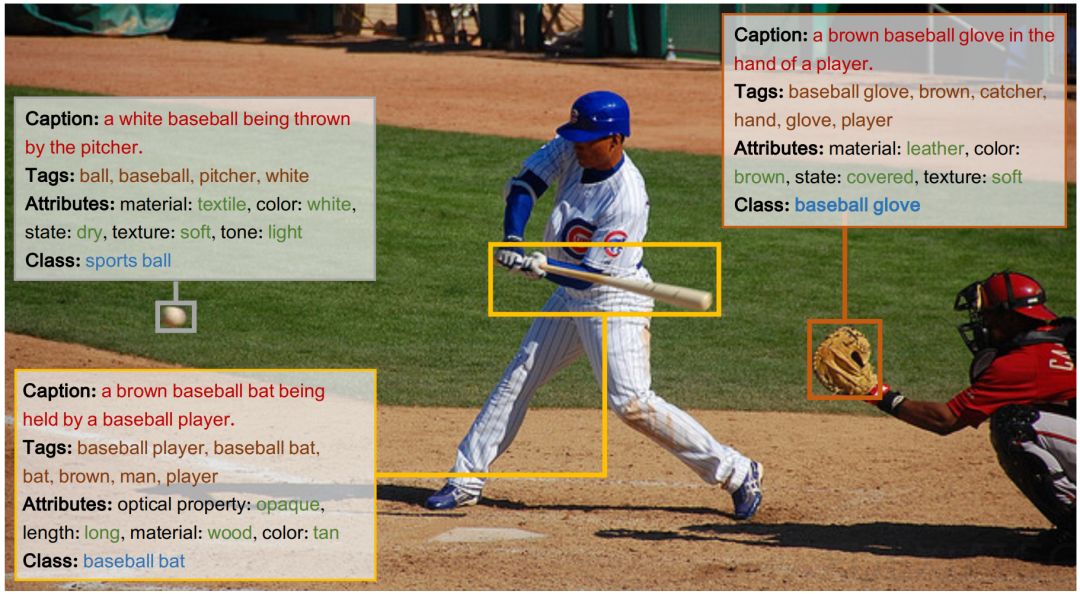
DynRefer是一种新型的区域级多模态理解模型,由中国科学院大学LAMP实验室的研究人员开发,旨在通过模拟人类视觉认知过程,提高区域级多模态任务的识别能力。该模型在RefCOCOg数据集的区域级字幕生成任务上取得了115.7 CIDEr的优异成绩,超越了其他CVPR 2024的方法。
区域级多模态任务的目标是将图像的特定区域转换为符合人类偏好的语言描述。DynRefer通过模拟人眼的动态分辨率机制,实现了对关注区域的高分辨率编码和对非关注区域的低分辨率编码,从而提高了编码效率和能力。这种动态分辨率方案克服了现有模型采用固定分辨率编码的局限。
DynRefer的核心方法包括多视图构建,以模拟动态分辨率图像。由于主流预训练视觉语言模型如CLIP只能接收均匀分辨率的输入,DynRefer通过构造多个均匀分辨率的视图来实现动态分辨率效果。在指代区域,模型提供高分辨率视图,在非指代区域则提供低分辨率视图。原始图像被裁剪并调整大小为多个候选视图,其中包含参考区域的视图被固定保留,以保留区域细节。
在训练过程中,DynRefer从候选视图中随机选择多个视图,以模拟由于注视和眼球快速运动而生成的图像。这些视图对应于不同的插值系数,有助于提高模型对区域细节的捕捉能力。实验证明,这种多视图方法对于所有区域多模态任务都至关重要。
DynRefer的研究成果已在论文”DynRefer: Delving into Region-level Multi-modality Tasks via Dynamic Resolution”中详细阐述,论文和代码已公开发布。这项工作为区域级多模态理解领域提供了一种新的视角,通过模拟人类视觉认知机制,实现了对图像区域更精准的理解和描述。
原文和模型
【原文链接】 阅读原文 [ 4244字 | 17分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


