文章摘要
【关 键 词】 大模型、内存计算、推理加速、内存瓶颈、异构架构
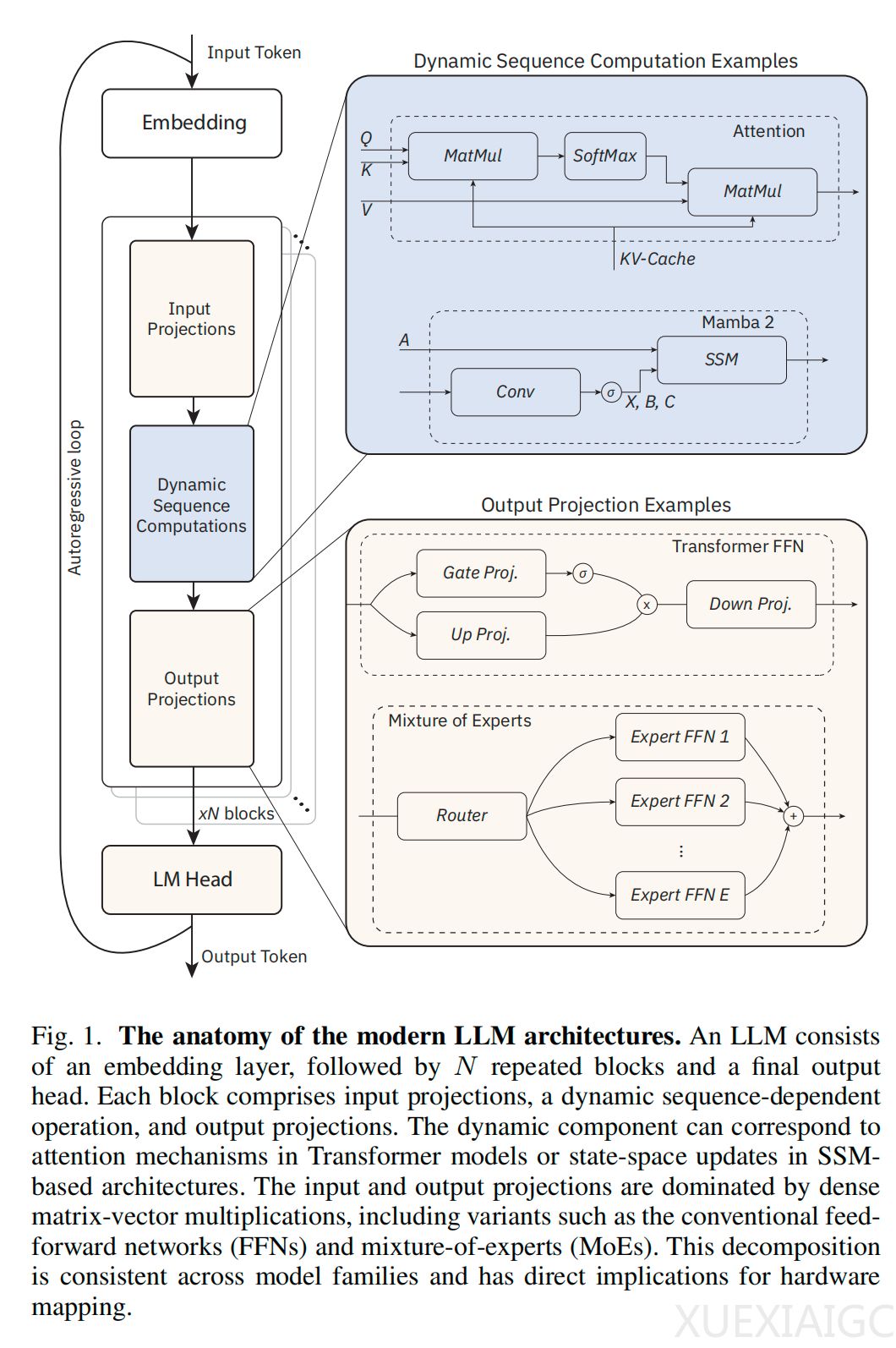
大型语言模型的快速发展使人工智能硬件的主要瓶颈从计算能力转移至内存容量与数据传输。模拟内存计算通过在内存阵列中直接执行矩阵向量乘法,显著减少了与模型权重相关的数据传输,成为应对内存瓶颈的极具前景的技术途径。现代大模型架构主要由静态的参数化计算和动态的序列相关操作组成,这两类操作对硬件设计提出了不同要求。
模拟内存计算主要分为易失性和非易失性两种实现方式。基于非易失性存储器的方案具备高片上权重密度,天然适用于推理过程中权重固定且复用率极高的静态计算。然而,大模型推理中的动态组件涉及操作数的频繁变化与低重用性,导致数据移动主导了执行过程。随着输入序列长度的增加,动态计算在整体工作负载中的比例逐渐上升,这使得模拟内存计算能够有效加速的操作比例相应下降。
释放模拟内存计算效率的关键在于提升片上存储密度,三维集成技术为此提供了有效的容量扩展路径。同时,通过模拟硬件感知训练等技术可以有效缓解设备噪声对推理精度的负面影响。鉴于单一架构难以同时高效处理静态与动态工作负载,将模拟内存计算加速器与数字处理器解耦的异构架构成为更优的系统级解决方案。在这种架构中,模拟内存计算专门负责高复用性的静态模型权重计算,而数字加速器则定制化地处理动态的序列相关操作。
模拟内存计算在解决大模型推理内存瓶颈方面展现出巨大潜力,但受限于动态计算组件的扩展性,其难以作为独立的推理解决方案。在未来的数据中心与边缘端部署中,模拟内存计算将主要作为异构推理系统中的专用协处理器,通过与数字加速器的协同工作,实现推理效率与能效的全面最优化。
原文和模型
【原文链接】 阅读原文 [ 4028字 | 17分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


