文章摘要
【关 键 词】 AI技术、语言模型、注意力机制、线性注意力、模型优化
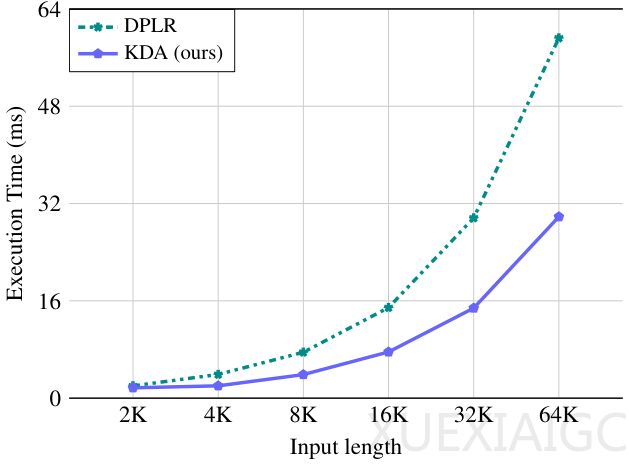
月之暗面团队开发的Kimi Linear模型通过创新的混合线性注意力架构,在公平比较中全面超越传统全注意力机制,实现了推理速度与模型性能的双重突破。该模型的核心创新在于Kimi Delta Attention(KDA)模块,它采用细粒度门控机制动态管理记忆状态,既解决了传统线性注意力记忆容量有限的问题,又保持了线性计算复杂度优势。KDA通过为每个记忆维度配备独立遗忘门,实现了对长序列信息的精确控制,其硬件优化算法使计算效率比通用实现提升约100%。
模型采用3:1的混合架构设计,每3个KDA层后插入1个无位置编码的全注意力层,形成效率与能力的黄金平衡。这种设计使KDA成为主要的位置感知算子,而全局注意力层则专注于捕捉长距离依赖关系。实验数据显示,在1.4万亿token预训练后,Kimi Linear在MMLU、GSM8K等基准测试及中文评测CEval中全面领先。其128k长上下文处理能力尤为突出,在RULER评测中平均得分达54.5,显著优于基线模型。
效率方面,Kimi Linear在百万级序列长度下展现出显著优势:预填充速度提升2.9倍,解码速度提升6倍,KV缓存减少75%。强化学习场景中的表现同样亮眼,数学问题求解的准确率增长率明显高于传统架构。这些突破源于团队对注意力机制本质的重新思考——KDA本质上是一种可学习的位置编码系统,其动态调整能力克服了固定编码方式的局限性。
该研究不仅提供了具体的技术方案,更开创了高效大模型设计的新范式。通过开源内核实现和模型检查点,团队推动了整个AI社区在长上下文建模领域的发展。这项工作证明,经过精心设计的线性注意力架构完全可以在所有场景下超越传统方案,为下一代语言模型的演进指明了方向。
原文和模型
【原文链接】 阅读原文 [ 3304字 | 14分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


