陈天奇新书上线:面向ML系统的现代GPU编程
文章摘要
【关 键 词】 机器学习、性能优化、底层开发、开源项目、编程指南
卡内基梅隆大学助理教授陈天奇近期发布免费在线书籍《Modern GPU Programming For MLSys》。该书脱胎于其开设的机器学习系统课程,聚焦大模型训练与推理中高性能GPU kernel编写方法,以Blackwell架构为主线,结合矩阵乘法与FlashAttention作为实战案例。陈天奇在开源系统领域积累深厚,主导过Apache TVM等多个知名项目。
大模型训练和推理的端到端速度往往取决于少数几类GPU kernel的实现质量。随着GPU架构演进,仅依赖传统优化技巧已无法编写出高效kernel,开发者必须同时具备硬件认知与实操理解。该书精准瞄准此挑战,致力于填补大模型底层高性能计算知识空白,帮助开发者掌握软硬件结合方法。
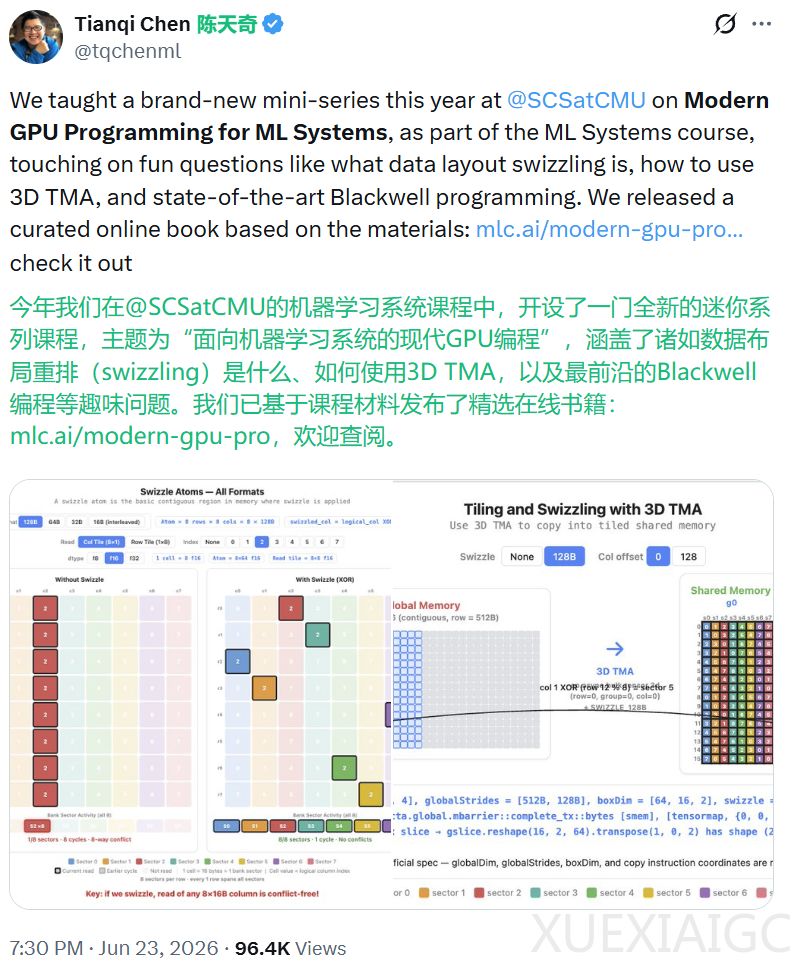
全书内容分为四大部分。第一部分剖析GPU执行模型与核心概念以奠定硬件直觉基础;第二部分介绍Python DSL TIRx,使读者能通过可运行代码精确控制底层细节。第三部分以矩阵乘法为例,展现从基础实现到引入异步加载及warp专精化的性能优化路径。第四部分构建出包含在线softmax重缩放等细节的完整FlashAttention 4注意力机制kernel。书末附有语言参考手册。
该套内容直接对标Blackwell架构编程实践,覆盖数据布局与异步数据搬运等工程问题。通过丰富图文材料与交互式演示,该书弥补了课程未录制视频的缺憾,为研究机器学习系统底层机制的开发者提供极具实战价值的指南。
原文和模型
【原文链接】 阅读原文 [ 1079字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-plus
【摘要评分】 ★★☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

