文章摘要
【关 键 词】 3D视频生成、Vid3D模型、动态渲染、高斯溅射、性能评估
在传统的3D视频生成领域,存在两种主要方法:一种是依赖2D视频模型和静态3D场景模型的分类器来优化动态3D视频场景的表示,这种方法对计算资源的需求极高,生成一个3D视频可能需要数小时;另一种是通过变形初始的3D场景表示来实现,但这种方法需要严格的时间结构和复杂的参数调整。
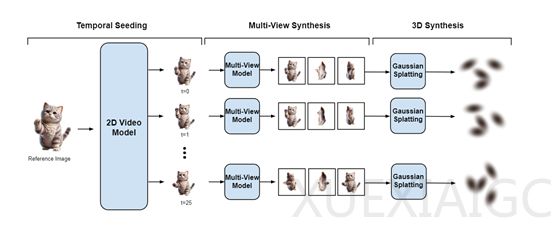
为了克服这些挑战,麻省理工学院、Databricks马赛克科研所和康奈尔大学联合推出了一种创新的模型Vid3D。Vid3D模型的核心思想是,不需要显式地建模3D时间动态,而是通过生成2D视频的时序动态轮廓,然后为视频中的每一帧独立生成3D表示,这样做的好处是不需要考虑前后帧之间的时间连贯性,从而降低了计算复杂度。
Vid3D的工作流程可以概括为以下几个步骤:首先,从一张参考图像开始,生成场景的2D视频种子,这个过程被称为“时序播种”,目的是捕捉场景随时间变化的动态特征。接着,通过查询一个2D视频模型并输入参考图像,Vid3D能够获得动态渲染的对象,尽管此时仅限于单一视角。这一步骤类似于在制作动画前先绘制关键帧的故事板,为后续步骤提供了动态变化的基础框架。
在多视图合成阶段,Vid3D针对种子视频中的每个时间步,独立生成多个视图,以丰富场景的细节并增强3D表示的准确性。Vid3D采用了高斯溅射方法来生成3D场景的连续表示,这是一种基于点云的方法,通过在3D空间中散布大量的点,并为每个点分配一个高斯权重来表示场景的表面。这些点的集合及其高斯权重共同定义了场景的3D形状和外观。
在3D视频合成阶段,Vid3D将每个时间步的多视图集合转化为3D表示,使用的是Gaussian Splatting技术,这是一种将2D图像转换为3D几何结构的有效手段。通过训练一个Gaussian Splatting模型,Vid3D能够基于先前生成的多视图集合,构建出每个时间步的3D场景。
为了评估Vid3D的性能,研究人员使用了最新的评估基准,并采用CLIP-I分数作为定量评估指标。在测试中,Vid3D的CLIP-I分数为0.8946,高于Animate124的0.8544,显示出其在生成动态3D视频场景方面的卓越性能。此外,研究人员还对Vid3D中每个时间步生成的视图数量进行了消融实验,发现随着视图数量的减少,CLIP-I分数略有下降,但性能变化不大,表明Vid3D在视图数量减少的情况下仍能保持较高的性能。
综上所述,Vid3D模型通过创新的方法,有效地降低了3D视频生成的计算复杂度,同时保持了高质量的3D视频输出,为AIGC领域的专业社区提供了一个有力的工具。
原文和模型
【原文链接】 阅读原文 [ 1471字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


