文章摘要
【关 键 词】 多模态模型、参数优化、数据质量、强化学习、推理机制
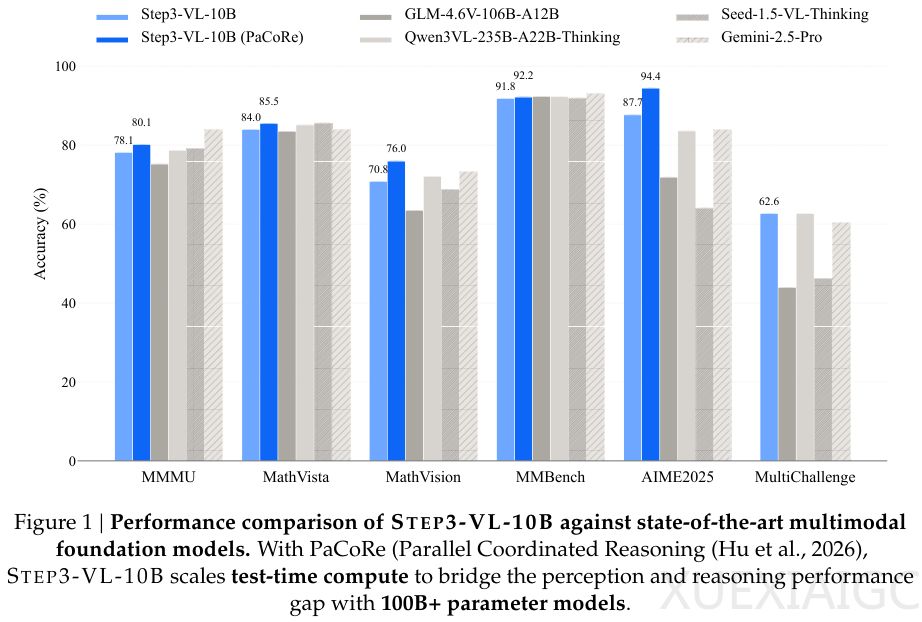
阶跃星辰多模态智能团队最新开源的STEP3-VL-10B模型以100亿参数规模实现了超越千亿参数模型的性能突破。该模型在数学推理、视觉感知及复杂指令遵循等任务中,不仅超越了同量级模型,还在多项基准测试中击败了参数量大其10至20倍的GLM-4.6V-106B、Qwen3-VL-235B及Gemini-2.5-Pro等闭源旗舰模型。其成功的关键在于极致的数据质量与创新的并行协同推理(PaCoRe)机制,证明了轻量级模型通过精准设计同样能够承载前沿多模态智能。
模型架构采用18亿参数感知编码器与Qwen3-8B解码器的组合,通过16倍空间下采样的投影器连接,有效解决了传统视觉骨干网络在多模态训练初期的收敛缓慢问题。多裁剪策略的运用使模型能够像阅读文章一样解析图像,通过全局与局部视图的并行处理保留关键语义信息。预训练阶段引入1.2万亿高质量多模态Token,构建了覆盖教育、OCR、GUI等领域的精细化数据集,其中教育领域样本达1500万条,为模型处理复杂文档与图表理解奠定了坚实基础。
全参数解冻训练策略是模型性能跃升的核心创新。在37万步迭代中,感知编码器与语言解码器始终保持同步更新,实现了视觉特征与语言表征的深度耦合。两阶段学习率调度策略(前9000亿Token广泛学习,后3000亿Token专注细粒度能力)进一步优化了训练效果。监督微调阶段采用文本主导到多模态平衡的渐进式对齐,确保逻辑严密性不丢失;强化学习阶段则通过PPO算法与二元奖励系统(感知奖励+生成式奖励)打磨模型输出质量。
模型在强化学习中展现出两类学习动力学特征:推理任务表现为思维链自然延长,感知任务则呈现熵减现象——输出长度缩减但准确性提升,揭示了不同认知机制的本质差异。PaCoRe机制通过并行生成视觉假设再综合验证的流程,模拟人类系统2思维,在MathVision等任务中实现5%以上的性能提升。实验显示,该机制使模型能主动交叉验证参考点坐标等复杂信息,将昂贵的慢思考转化为高效推理能力。
在超过60项基准测试中,STEP3-VL-10B的STEM推理能力(MMMU 80.11%、MathVision 75.95%)与视觉识别性能(MMBench中英文版超91%)均达到10B量级巅峰。其文本能力同样突出,AIME 2025数学竞赛94.43%的得分打破了多模态模型牺牲文本性能的惯例。GUI操作任务(ScreenSpot-V2 92.61%)的表现更预示了其在自动化代理领域的应用潜力。这一成果为小模型实现大智慧提供了可复现的技术路径,其数据构建、训练策略与推理机制的设计思路将对行业产生深远影响。
原文和模型
【原文链接】 阅读原文 [ 3047字 | 13分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


