2026开年关键词:Self-Distillation,大模型真正走向「持续学习」
文章摘要
【关 键 词】 大模型、自蒸馏、持续学习、强化学习、推理能力
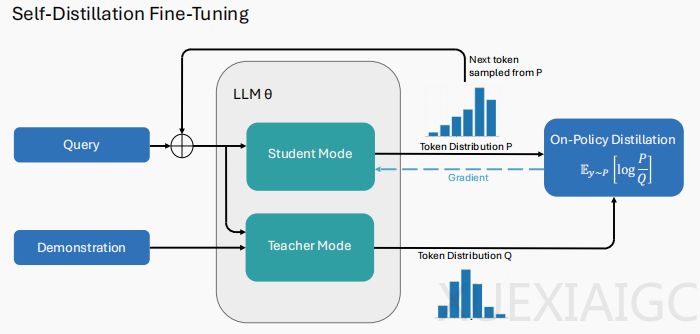
2026年初,大模型领域的研究焦点集中在自蒸馏(Self-Distillation)技术上,这一方法被视为解决持续学习瓶颈的关键突破。传统监督微调(SFT)在模型吸收新知识时容易引发灾难性遗忘,而自蒸馏微调(SDFT)通过构造少量专家演示的上下文,诱导模型生成高质量的教师分布,再通过自蒸馏拟合这一分布。这一技术将持续学习转化为策略内对齐问题,有效避免了参数漂移,在技能学习和知识获取任务中表现优于SFT,显著减少遗忘现象。
在强化学习领域,传统方法依赖二值反馈导致信用分配困难和进化停滞。自蒸馏策略优化(SDPO)框架通过引入富反馈环境,将模糊的标量奖励转化为Token级密集监督信号,精准定位错误关键点。实验显示,SDPO在极难任务中的采样效率达到传统算法的3倍,在编程测试中仅需1/4样本量即可达到同等精度,突破了传统强化学习的性能瓶颈。
针对复杂推理任务中搜索空间过大和奖励信号稀疏的问题,策略内自蒸馏(OPSD)框架通过构建模型内部的信息不对称性,利用特权信息生成高质量教师分布,引导学生策略实现内生推理能力对齐。在高难度数学推理基准测试中,OPSD的Token利用率比传统方法高4-8倍,显著提升了模型的深层逻辑推导能力。
这三项研究的共同点在于利用模型内生能力,通过上下文构造信息差实现自驱动升级。自蒸馏技术正成为大模型后训练阶段的标准配置,其核心价值在于不依赖外部强教师即可实现持续学习。这一趋势表明,未来大模型的进化可能更依赖于自身学习机制的优化,而非外部干预。
原文和模型
【原文链接】 阅读原文 [ 1872字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★☆☆


相关文章


