73年前,香农已经给大模型发展埋下一颗种子
文章摘要
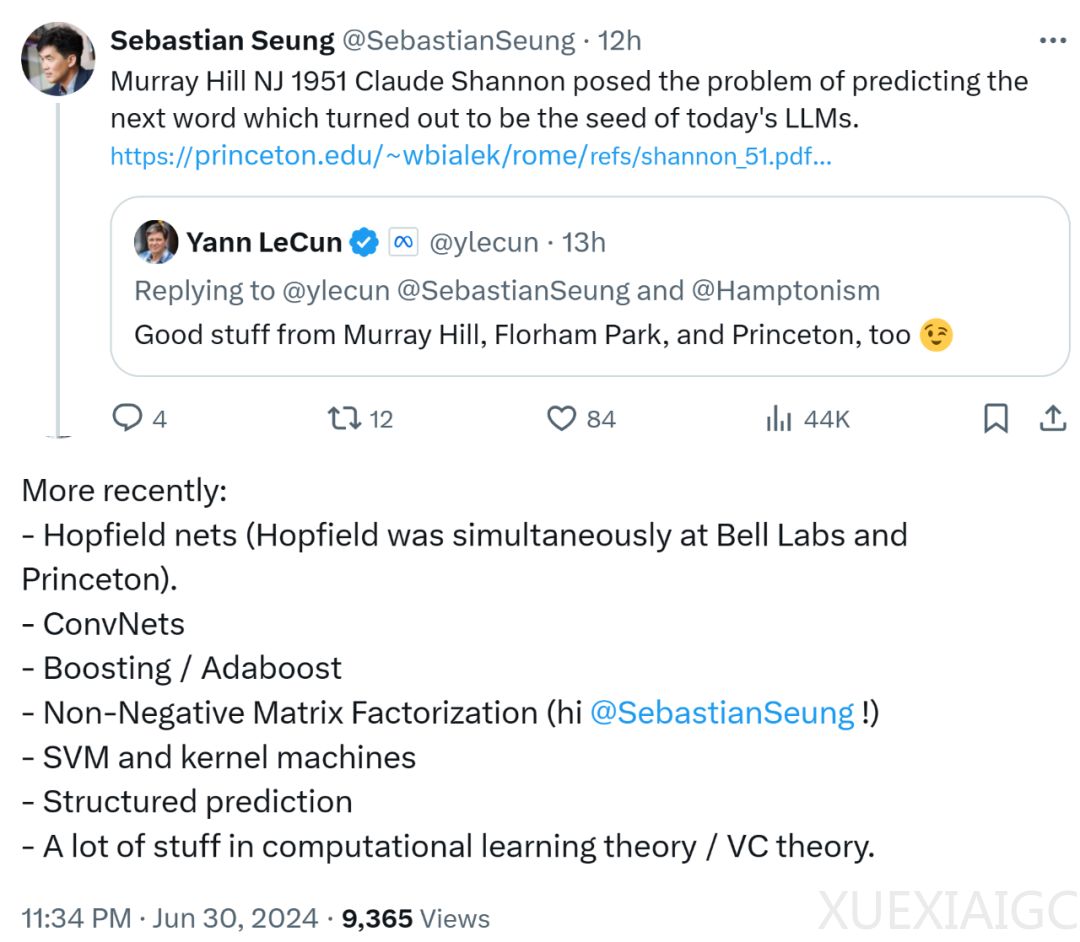
普林斯顿大学教授承现峻提出,1951年克劳德·香农在贝尔实验室提出的预测下一个单词的问题,成为了当前大语言模型(LLM)的基础。
香农在论文中给出了两种估计英语熵的方法,并通过N-gram模型计算英语的熵。随着N的增加,熵接近英语的实际熵值。
香农还通过实验让受试者猜测短语中的字母,发现英语的冗余度约为69%。
香农的研究对现代计算机科学和自然语言处理(NLP)有深远影响。通过学习大量文本数据,现代大语言模型能够预测下一个词或下一段话的可能性,从而更好地理解和生成人类语言。
香农的工作为信息论和计算机科学奠定了基础,影响了后来的Hopfield网络、ConvNets、Boosting/Adaboost、非负矩阵分解、支持向量机(SVM)等重要研究成果。
香农的研究还展示了如何通过统计方法计算英语的冗余度,并提出了压缩算法如Huffman压缩和Lempel-Ziv压缩,以提高存储效率。
尽管现代计算机拥有足够大的内存,但这些压缩算法在存储文本时仍能节省大量空间。
香农的研究不仅在理论上具有重要意义,还在实际应用中展示了其价值。通过理解语言的统计特性,可以开发出更高效的语言模型和压缩算法,为信息处理和传输提供更好的解决方案。
香农的工作展示了信息论在语言处理中的应用,为现代人工智能的发展提供了重要的理论基础。
原文和模型
【原文链接】 阅读原文 [ 2810字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 gpt-4o
【摘要评分】 ★★★★★

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

