文章摘要
【关 键 词】 大模型、智能体、自动优化、代码演化、架构搜索
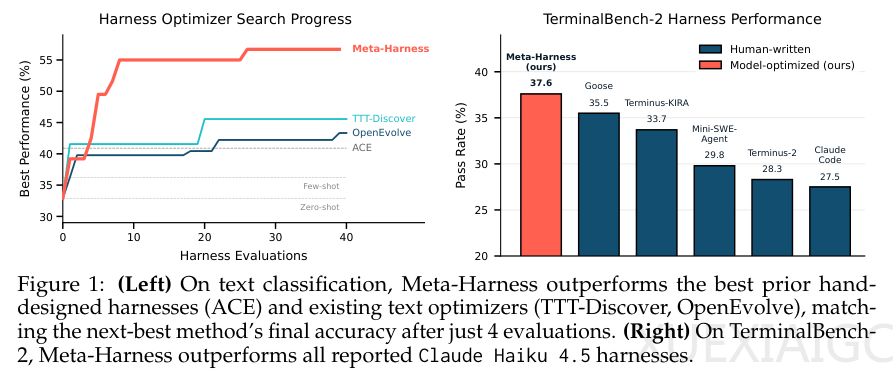
在三大核心测试领域,Meta-Harness均取得显著领先。 在在线文本分类任务中,其自动发现的架构以48.6%的平均准确率大幅超越ACE和MCE等人工方案,并将上下文消耗降低至后者的五分之一以下;在分布外(OOD)数据集上,仍以73.1%的平均准确率稳居第一。数学推理方面,系统在无任何人工干预下重构BM25检索栈,于IMO级别难题上平均提升4.7分,且在五个不同基础模型上均稳定优于手工调校的基准。长周期编程测试中,基于Opus 4.6的Meta-Harness架构通过率达76.4%,超越顶级人类团队开发的Terminus-KIRA;在轻量级Haiku 4.5模型上优势更为明显,通过率高出第二名2.1个百分点。
系统展现出强大的自主纠错与策略演化能力。 智能体在早期迭代中尝试混合修改方式导致性能下滑后,能迅速通过日志分析定位干扰源,剔除无效变更并转向增量式安全修改。整个优化过程未预设硬编码规则,仅依赖基础领域引导,却能在数小时内生成高可读性、跨平台兼容的高质量代码。这预示未来AI系统开发可能演变为一种“元编程”范式:开发者只需设定边界与工具接口,其余交由AI在试错中自主编译与演化。
原文和模型
【原文链接】 阅读原文 [ 3344字 | 14分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3-max-2026-01-23
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

