文章摘要
【关 键 词】 人工智能、大语言模型、蒙特卡洛树、自我批评、智能体性能
在人工智能领域,尤其是大语言模型(LLM)的发展和应用落地方面,一个重要的进步是AGI平台MultiOn和斯坦福研究人员联合开发的智能体Agent Q。Agent Q在自然语言处理任务中展现出了显著的泛化能力,特别是在需要搜索、比较和选择的交互式、多步骤环境中。
Agent Q的核心是蒙特卡洛树搜索(MCTS)算法,这是一种启发式搜索算法,广泛应用于游戏和决策领域。在Agent Q中,MCTS用于在网页环境中导航,通过模拟可能的未来路径来评估和选择最优的行动策略。该算法涉及选择、扩展、模拟和反向传播四个阶段,通过迭代优化搜索树来提高策略性能。
然而,MCTS算法在复杂环境中面临的一个挑战是环境奖励的稀疏性,这可能导致智能体在长期任务中遇到困难。为了解决这个问题,Agent Q引入了自我批评机制,这是一种自我评估过程,智能体在每个决策节点上使用自身的评估来提供中间奖励。这种机制不仅帮助智能体进行自我监督,而且通过提供即时反馈指导智能体学习正确的规划路径。
Agent Q的自我批评机制依赖于一个反馈语言模型,该模型对智能体在每个节点上可能采取的动作进行评分,形成一个加权分数。这个分数结合了MCTS的平均Q值和反馈语言模型生成的分数,用于构建直接偏好优化(DPO)算法中的对比对。DPO算法是一种离线强化学习算法,通过比较不同动作的偏好来优化策略,使智能体能够从成功和不成功的轨迹中学习。
Agent Q框架的另一个特色模块是迭代式微调,这是实现自我学习的关键。与传统的监督学习不同,迭代式微调允许智能体在没有明确标签的环境下进行学习,通过自我生成的数据和偏好对来指导优化过程。
在网络交互中,智能体的状态可能部分不可观察,因此构建一个有效的状态表示对于智能体的性能至关重要。Agent Q采用了一种紧凑的历史表示方法,将智能体迄今为止生成的动作和当前浏览器状态结合起来,形成了一个高效的内存组件。
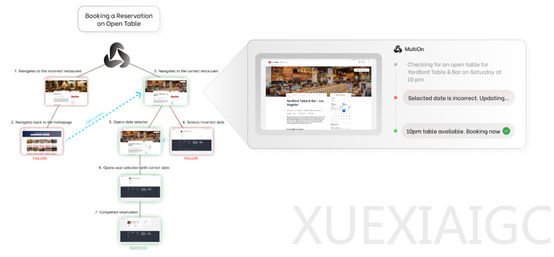
为了测试Agent Q的性能,研究人员在模拟电子商务平台WebShop进行了综合测试。实验结果显示,Agent Q的表现显著优于行为克隆和强化学习微调的基线模型,在某些任务中甚至超过了平均人类表现。特别是在真实世界的预订场景中,Agent Q将Llama-3 70B模型的零样本成功率从18.6%提升至81.7%,相对提升了340%,并在配备在线搜索功能后,成功率进一步提高到了95.4%。
总的来说,Agent Q的开发展示了在复杂多步骤推理任务中,通过自我学习和评估机制,智能体能够显著提高其泛化能力和性能。这一进步为AIGC领域的专业社区提供了宝贵的参考和启示,有助于推动大语言模型在更广泛场景中的应用和发展。
原文和模型
【原文链接】 阅读原文 [ 1203字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


