Clawdbot 之后,我们离能规模化落地的 Agent 还差什么?
文章摘要
【关 键 词】 AI技术、Agent挑战、基础设施、成本控制、状态管理
OpenClaw(原名Clawdbot)的爆火引发了行业对AI Agent规模化落地的深入讨论。尽管个人极客对其兴趣浓厚,但企业和商业环境面临的核心问题迅速显现:高昂的Token消耗、模糊的安全边界、隐私风险以及协作困难。当前Agent更多停留在惊艳的Demo阶段,尚未成为可规模化的产品。Monolith砺思资本的技术沙龙“After the Model”聚焦了这一议题,探讨了Agent规模化落地的关键障碍。
Agent需要成为可持续工作的系统,而非单次任务的跑通。这一观点被反复强调,凸显了仅依赖“模型智力”的不足。工程化挑战的核心在于稳定性、高吞吐量、成本控制和精确的状态管理。以GUI Agent为例,其数据标注依赖高成本的人力资源,例如雇佣985高校博士生,单条数据标注耗时20分钟,导致数据规模受限。这种“用黄金盖平房”的模式不可持续,行业被迫转向强化学习(RL),通过虚拟环境中的自我试错降低边际成本。然而,RL同样面临算力门槛,工业级训练需16张显卡和大量CPU资源,对中小企业构成显著负担。
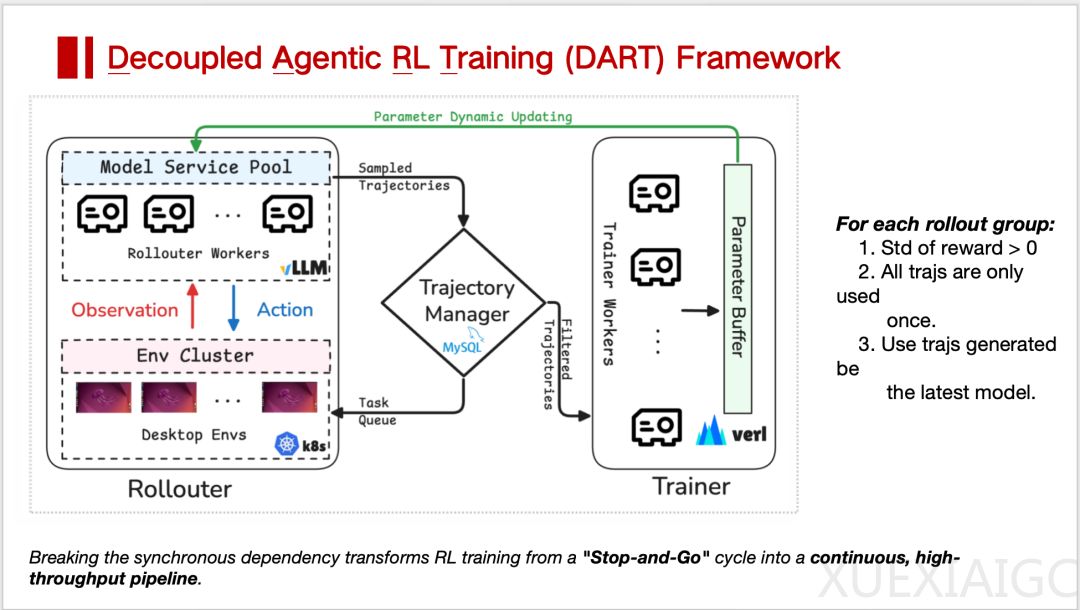
训练环境的低效是另一大瓶颈。GUI Agent的交互延迟高达30秒以上,远低于传统RL任务的毫秒级反馈。这种“光速GPU配龟速操作系统”的悖论导致计算资源严重浪费。此外,GUI Agent的动作空间接近无限,奖励稀疏性加剧了训练难度。解决这一问题需要构建高仿真环境,并通过解耦架构提升效率。例如,Dart框架通过异步采样与训练分离,实现了5.5倍的环境利用率提升和训练吞吐量翻倍。轻量化设计如模块化框架和CPU Offload技术进一步降低了算力门槛。
状态管理的缺陷是Agent落地的另一障碍。Transformer架构缺乏显式存储器,难以处理长程逻辑推理。学术界尝试通过State Space Models(SSM)、Linear Attention等新架构弥补这一不足,或转向“代码思考”以提升精确性。记忆管理被划分为用户侧和执行侧,后者对Agent的自我进化至关重要。分层存储设计(如file system式结构)成为优化方向,而非单纯依赖长上下文窗口。企业级应用的核心需求是Agent能否记住历史交互和业务规则,而非技术细节。
护城河从模型能力转向系统整合能力。开源模型的普及使得工程化能力成为差异化关键。未来的赢家可能是那些在基础设施、数据闭环和记忆管理上表现突出的团队。Agent Native Infra(如异步训练框架、虚拟训练场)成为被低估的洼地,而仿真环境生成的高质量合成数据将成为稀缺资源。行业共识是,Agent的深水区刚刚开始,工程化与创新并重将是突破的核心。
原文和模型
【原文链接】 阅读原文 [ 3502字 | 15分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


