文章摘要
【关 键 词】 大模型、智能编程、模型训练、马斯克、稀疏机制
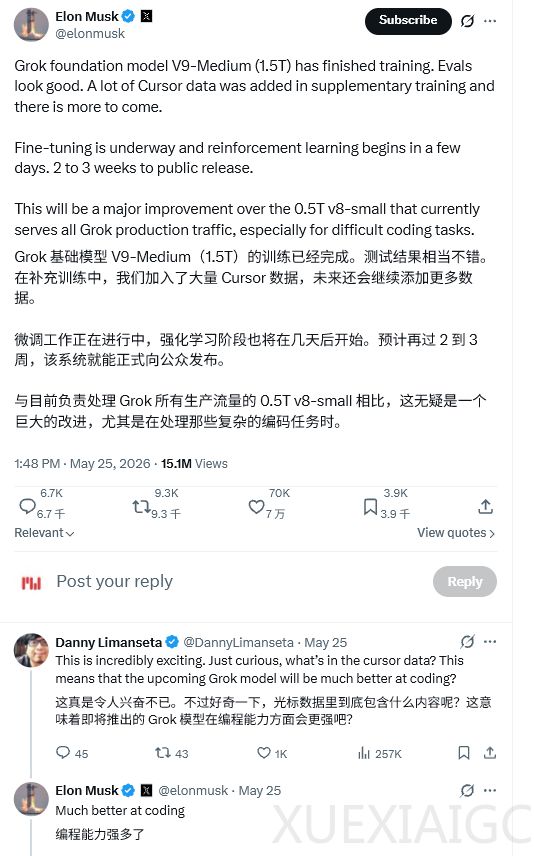
近期,人工智能领域在大语言模型的研发与应用方面取得了显著进展,其中Grok-5与MiniMax-M3两款新模型的动态备受瞩目。马斯克宣布,拥有1.5万亿参数的Grok-5已完成训练,并计划在两到三周后向公众发布。该模型的参数量达到了现役模型的三倍,预计将推动推理深度和复杂任务处理能力迈上新的台阶。目前,Grok的全部生产流量仍运行在参数量较小的Grok-4上,新模型的规模跃迁意味着整体性能的全面升级。
在Grok-5的训练过程中,数据质量与来源成为核心焦点。该模型在补充训练中引入了大量来自AI编程工具Cursor的真实开发者编码轨迹数据,以此大幅提升在编程场景下的实战表现。Cursor积累了海量涵盖代码补全、重构与调试的高质量交互数据,这些包含完整思维链的交互记录对训练编程模型具有极高价值。此外,SpaceX与Cursor已达成深度合作,通过提供超级计算机算力与获取期权的方式,实现了算力与数据产品的强强联合。xAI利用这些优质编码数据训练Grok基础模型,旨在强化其编程能力,从而在编码领域与业界领先同类产品展开正面竞争。
另一方面,MiniMax团队也透露了新一代模型MiniMax-M3即将发布的消息。MiniMax-M3将采用全新的稀疏注意力机制,其预填速度和解码速度分别实现了近十倍和十五倍以上的显著提升。伴随新模型的预热,官方正式发布了M2系列的技术报告,宣告M2系列开发工作的终结。这一系列动作标志着底层架构优化与模型迭代迈出了重要一步,相关研发重心已全面转向新一代大语言模型的部署与应用落地。
原文和模型
【原文链接】 阅读原文 [ 613字 | 3分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.7-max
【摘要评分】 ★☆☆☆☆


相关文章


