LLM近期重大架构进化一览:从Gemma 4到DeepSeek V4
文章摘要
【关 键 词】 模型架构、长上下文、KV缓存、推理优化、机制创新
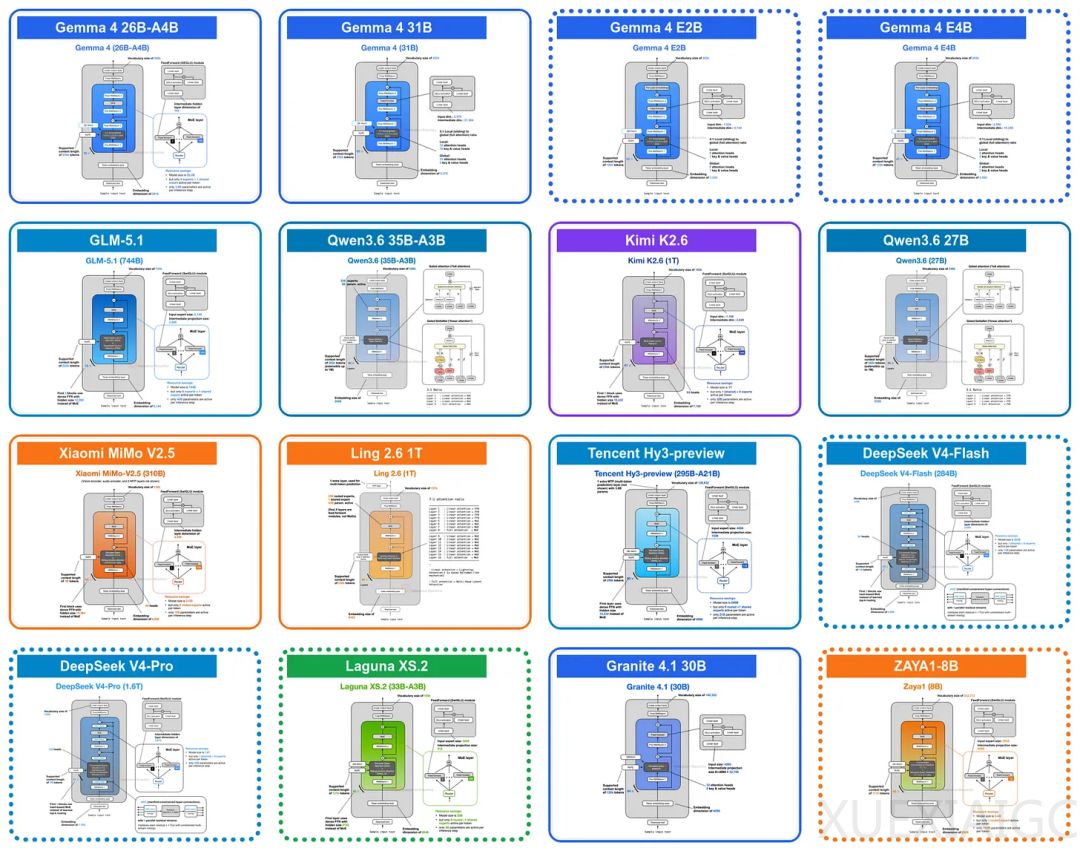
随着大模型上下文窗口不断扩展,KV缓存膨胀与注意力计算成本飙升已成为制约长序列推理的核心瓶颈。近期多款主流开源模型的架构演进表明,降低长上下文推理的计算与存储开销已成为大模型底层设计的核心趋势。Google推出的Gemma 4系列率先大规模应用跨层KV共享机制,通过让后续Transformer层直接复用前层计算的键值张量,使KV缓存体积缩减近半,大幅缓解了长文本场景下的显存压力。该模型同步引入逐层嵌入技术,在不扩张核心计算图的前提下,利用独立的嵌入切片增强令牌特定信息的表达能力,实现参数效率与模型容量的双重优化。
在注意力算力的精细化调度方面,Poolside的Laguna XS.2采用逐层注意力预算策略,摒弃传统的均等化头部分配,依据滑动窗口与全局注意力的计算代价差异,动态配置各层查询头数量,确保高昂的全局访问能力被集中用于关键层级。Zyphra发布的ZAYA1-8B则部署压缩卷积注意力机制,将查询、键、值同步映射至低维潜在空间执行注意力运算,并在压缩向量上叠加卷积混合以注入局部序列依赖。该方案从注意力计算源头削减了浮点运算量与缓存需求,突破了传统仅压缩KV缓存的局限。
DeepSeek V4进一步将流形约束超连接引入残差路径,配合压缩稀疏注意力模块,在旗舰级混合专家模型中完成了新型拓扑结构与长序列缓存优化的规模化验证。整体而言,大模型架构正从粗放式规模扩张转向底层计算范式重构,通过状态复用、潜在空间运算与动态资源分配等系统性创新,在保障长上下文连贯性的同时彻底重塑了推理成本曲线。
原文和模型
【原文链接】 阅读原文 [ 6558字 | 27分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.6-max-preview
【摘要评分】 ★★★★☆


相关文章


