文章摘要
【关 键 词】 开源登顶、OCR革新、文心赋能、多模态突破、数据驱动
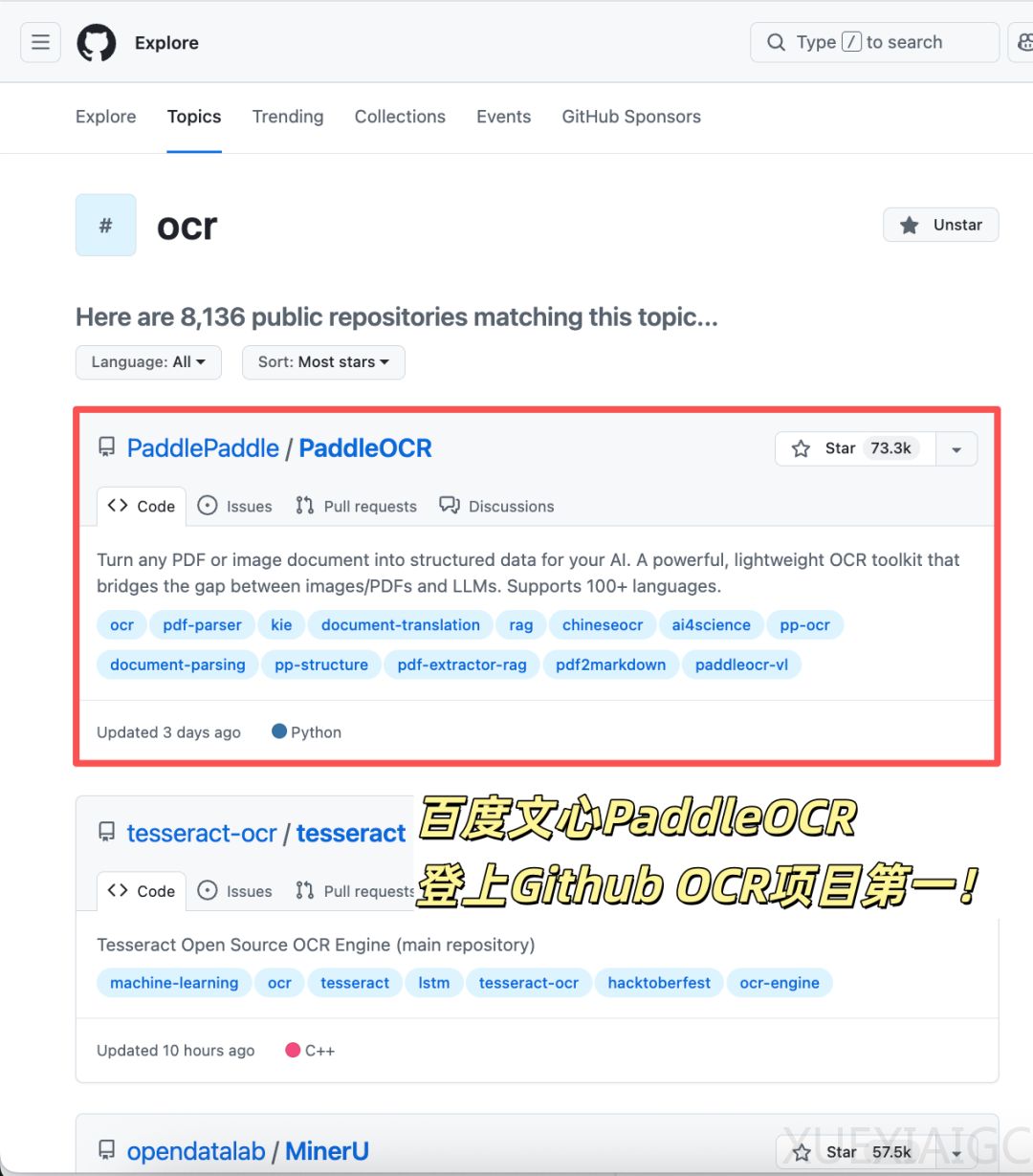
在AI大模型时代,百度文心大模型衍生的PaddleOCR项目正式超越谷歌Tesseract OCR,以73300+ Star登顶GitHub全球OCR项目榜首,实现中国开源在该基础赛道上首次全球Star第一。这一转变不仅标志着技术迭代完成,也反映了开发者社区对国产工具的高度认可,引发全球开发者热烈讨论。
PaddleOCR的崛起始于2020年,是深度学习时代原生构建的模型;2023年后伴随大模型浪潮,其与文心大模型形成双向赋能关系:PaddleOCR负责高精度文本提取,为大模型提供高质量“食材”;文心则通过多模态理解、跨模态融合及结构化输出能力反哺OCR,推动其从“识别”迈向“理解”。在此基础上,PaddleOCR-VL(0.9B参数)与VL-1.5接连发布,在OmniDocBench V1.5评测中分别取得92.6分和94.5分,综合性能超越GPT-4o、Gemini-2.5 Pro、Qwen3-VL等大量千亿级模型,获评全球第一,并首次实现异形框定位,精准处理倾斜、变形等复杂文档形态,为金融票据与档案数字化等场景提供切实解决方案。
技术层面上,PaddleOCR持续深耕底层创新,于CVPR 2026被收录两篇关键论文:PP-OCRv5以仅5M参数的轻量模型,在手写、多语言及自然场景下表现优于GPT-4o等大模型;其核心突破在于提出“数据为中心”的系统化优化策略,发现“难度甜点区”规律,验证特征多样性与小模型鲁棒性的优势,大幅降低计算成本却提升定位精度与准确性。另一项研究PaddleOCR-VL提出“由粗到细”架构,通过轻量级区域聚焦模块仅处理图像重点部分,将视觉Token数量压缩至竞品1/3–1/2,既保障精度又显著缓解算力瓶颈。
行业趋势显示,当前OCR已成为大模型竞争的关键基础设施,是连接现实世界与人工智能的核心入口。因海量非结构化信息仍沉淀于扫描件、合同、表格等离线载体中,OCR成为解锁这些数据的“钥匙”,直接支撑Agent理解与决策能力发展。多位行业专家已将OCR纳入教育内容——例如吴恩达今年新课便聚焦智能体文档提取;同时各大厂商密集推出新型OCR产品,形成“AI+OCR”生态群像竞争格局,比拼重心正从模型参数转向场景化适配与端云协同方案。
长远来看,OCR演进方向日益精细化,未来或聚焦垂直场景深度挖掘,或推进本地轻量化部署结合云端强化训练,进而催生真正意义上的全能信息处理助手。PaddleOCR登顶不仅是单一项目胜利,更是中国开源整体能力跃升的重要缩影,彰显了国内团队在基础软件领域实现全球影响力的里程碑意义。
原文和模型
【原文链接】 阅读原文 [ 2944字 | 12分钟 ]
【原文作者】 量子位
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★★★★★


相关文章


