文章摘要
【关 键 词】 AI评测、高考模拟、豆包模型、智能写作、理科挑战
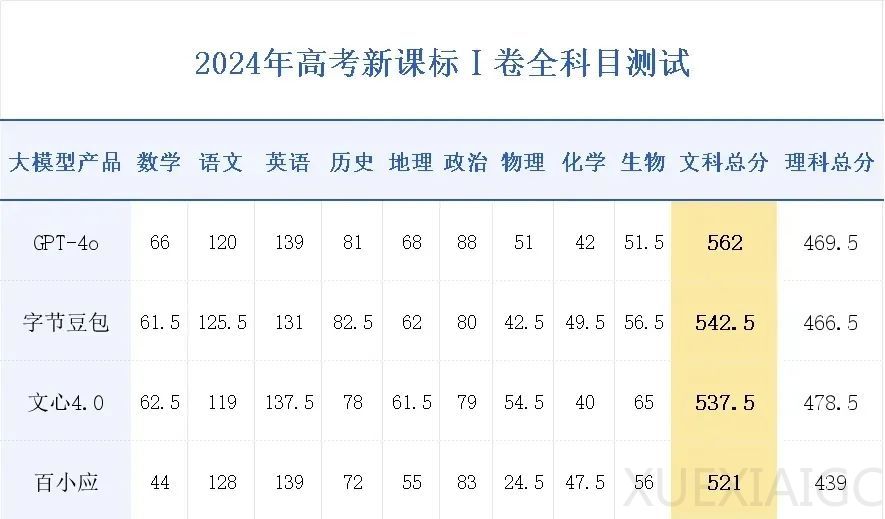
近期,一项针对大型AI模型进行的“高考大摸底”评测引起了广泛关注。在河南省高考文科一本线为521分的情况下,有四个大模型的得分超过了这个分数线。其中,GPT-4o以562分的成绩领先,而国产大模型中表现突出的是字节跳动的“豆包”,得分为542.5分。在语文和历史等科目上,“豆包”甚至超越了GPT-4o,显示出AI在语言和逻辑处理方面的优势。
评测榜单中,“豆包”在多个维度上的表现一致,无论是在智源研究院发布的FlagEval(天秤)的客观评测,还是在OpenCompass(司南)的评测中,“豆包”的成绩都紧随OpenAI之后。这表明“豆包”在知识运用和数学能力方面具有较高水平,甚至在某些方面超过了GPT-4。
通过实际测试“豆包”回答高考题目,可以发现其在写作文方面已经摆脱了模板式的写法,能够引经据典进行论证。然而,对于数学题目的解答,大模型的表现并不尽如人意。复旦大学自然语言处理实验室的测试显示,大模型在数学题目上的准确率存在一定的随机性,且不同模型生成的答案可能存在偏差。
技术圈内对于大模型在理科题目上的表现存在争议。一方面,大语言模型的基本原理是通过预测下一个token来生成内容,这种生成方式在面对需要推理和计算的理科题目时,准确率可能受限。另一方面,理科语料的稀缺也是导致大模型在理科方面表现不佳的原因之一。尽管如此,大模型仍在努力提升其推理和计算能力,以期达到更高的智能水平。
值得注意的是,“豆包”在手机端的“拍题答疑”功能中,通过RAG链路的方式,能够实现对数学题目的准确解答,显示出大模型在特定应用场景下的强大潜力。
综合各项评测和实际测试结果,可以认为“豆包”已经稳居国产大模型的第一梯队。其在短时间内取得显著成绩的背后,是其独特的发展路径和策略。尽管大模型在文科和理科方面的表现存在差异,但随着技术的进步和优化,未来大模型在各个领域的表现都值得期待。
原文和模型
【原文链接】 阅读原文 [ 3303字 | 14分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


