文章摘要
【关 键 词】 AlphaMath、蒙特卡洛树搜索、数学推理、大语言模型、自动化数据生成
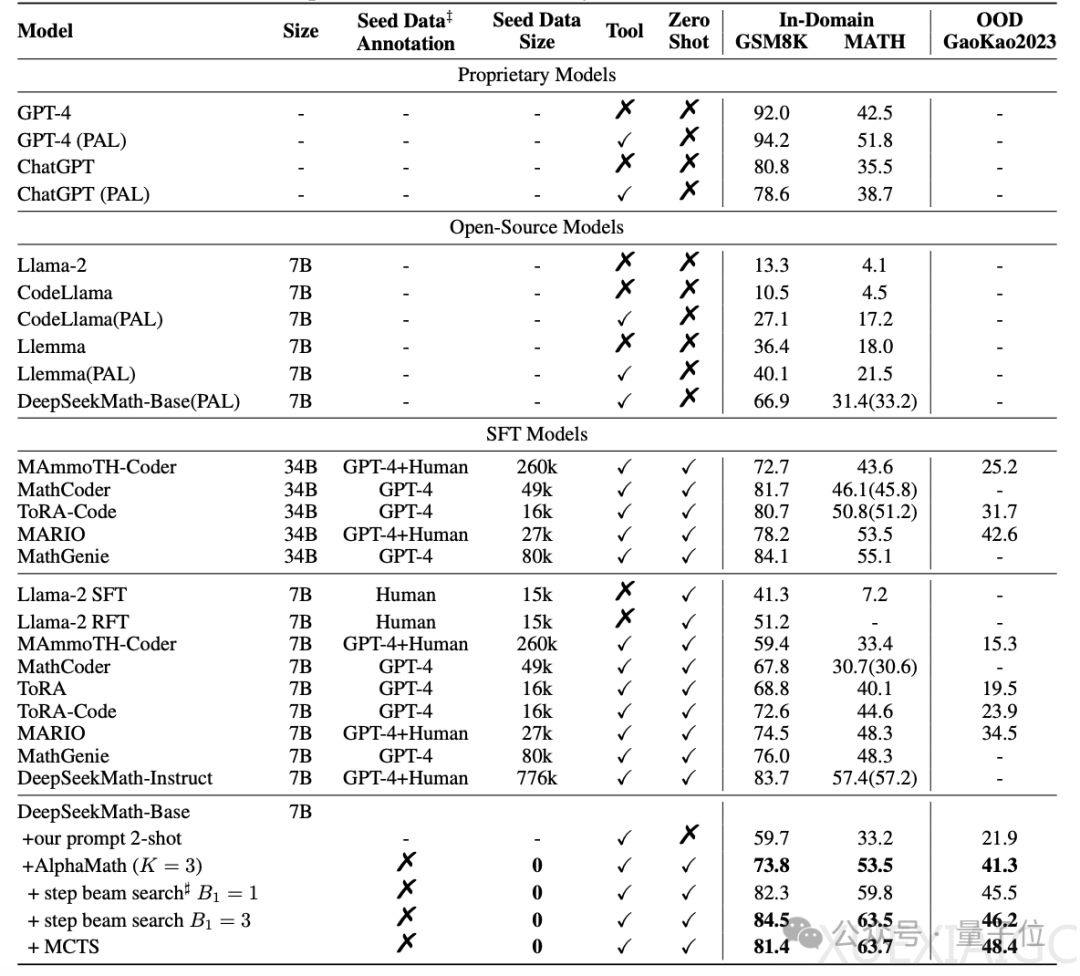
阿里巴巴的研究人员最近提出了一种名为AlphaMath的方法,该方法利用蒙特卡洛树搜索(MCTS)增强大语言模型(LLM)的性能,特别是在数学推理任务上。这项研究的核心在于自动化生成高质量的数学推理数据,而无需人工标注解题步骤,从而有效提升大模型的数学成绩。AlphaMath方法的提出,不仅提高了大模型在MATH数据集上的得分,甚至超过了GPT-4模型,而且也引起了人们对蒙特卡洛树搜索这一算法的重新关注。
AlphaMath的技术路线分为三个阶段。首先,研究人员收集了一个包含数学问题及其正确答案的数学数据集。然后,使用预训练的大模型生成初始的解题路径,并通过MCTS对解题路径进行探索和改进,以寻找更优的解题思路。同时,训练一个价值模型来预测解题路径的质量,从而引导搜索方向。最后,利用第二阶段获得的数据来优化策略模型和价值模型。这三个阶段通过迭代优化的方式执行,以实现自动数据生成和模型数学能力的提升。
此外,研究人员还提出了一种名为Step-level Beam Search的方法,以提高大模型的数学推理效率,平衡推理时的解题质量和运行时间。这种方法通过利用价值模型对候选路径进行评估,选择高质量的解题路径,并在搜索过程中动态调整候选路径集合,提高搜索效率。
为了验证AlphaMath的效果,研究人员对开源的数学大模型DeepSeekMath-Base-7B进行了训练,并在GSM8K、MATH和Gaokao2023基准上与其他模型进行了对比。结果显示,AlphaMath方法训练的7B数学大模型在MATH数据集上的得分达到了63%,超过了GPT-4原版的42.5%和外挂代码解释器版的51.8%。此外,在执行3轮MCTS并训练策略模型和价值模型的情况下,AlphaMath能让大模型在GSM8K上提升10多分,在MATH和Gaokao2023上提升20多分。Step-level Beam Search在MATH数据集上也取得了良好的效率和准确率平衡。
这项研究的共同一作是Guoxin Chen、Mingpeng Liao、Chengxi Li和Kai Fan,通讯作者Kai Fan是北京大学的本硕毕业生,2017年从杜克大学博士毕业后加入阿里巴巴达摩院。论文已发布在arXiv上,供学术界和工业界进一步研究和讨论。
原文和模型
【原文链接】 阅读原文 [ 1281字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


