文章摘要
【关 键 词】 计算机视觉、图像分割、多模态模型、语义理解、视频跟踪
Meta最新的SAM 3模型在计算机视觉领域实现了重大突破,将分割模型从简单的视觉交互工具升级为能理解语义概念的视觉-语言多模态模型。该模型通过可提示概念分割(PCS)技术,支持用户直接用文字描述(如”红色的苹果”)或图像示例来定位和分割目标,无需传统的手动标注。
模型架构方面,SAM 3在SAM 2基础上进行了创新性扩展,采用双编码器-解码器的Transformer架构。其核心创新”存在标记”设计将目标识别与定位解耦,使分类门控F1指标提升5.7个百分点。视频处理能力上,模型结合检测器和跟踪器,通过时间消歧策略解决遮挡问题,在52500个视频数据集上实现了连贯的目标跟踪。
为训练这一复杂模型,研究团队构建了高效的数据引擎系统。通过人类与AI标注员的协同工作,系统累计生成超过1.6亿个图像-短语对,数据生产效率比纯人工标注提升一倍。该引擎采用四阶段渐进式开发,最终覆盖15个不同领域的数据集,并建立了包含2240万节点的本体论知识库。
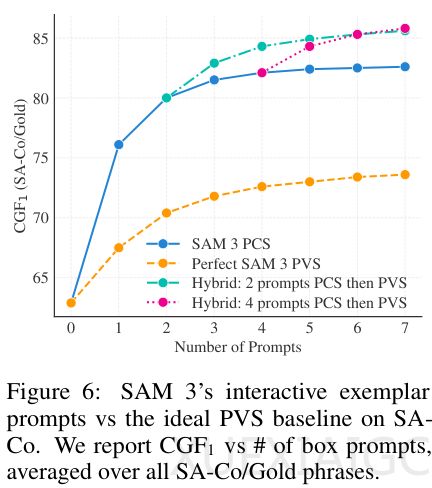
在性能评估方面,团队创建了包含21.4万独特短语的SA-Co基准测试。结果显示SAM 3在开放词汇识别任务中的表现达到人类水平的88%,零样本掩码AP值47.0创下新纪录。与多模态大语言模型结合后,其推理分割能力在ReasonSeg基准上实现零样本超越。处理单帧图像仅需30毫秒,视频场景下保持实时性能。
尽管在医疗影像等专业领域仍有局限,SAM 3的推出标志着计算机视觉从感知工具向理解系统的转变,为多模态AI发展提供了新的技术范式。其成功也展示了数据引擎方法在大模型训练中的关键作用,为行业树立了新的技术标杆。
原文和模型
【原文链接】 阅读原文 [ 3761字 | 16分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


