文章摘要
【关 键 词】 AI工程、智能体架构、上下文管理、多智能体协作、设计评审
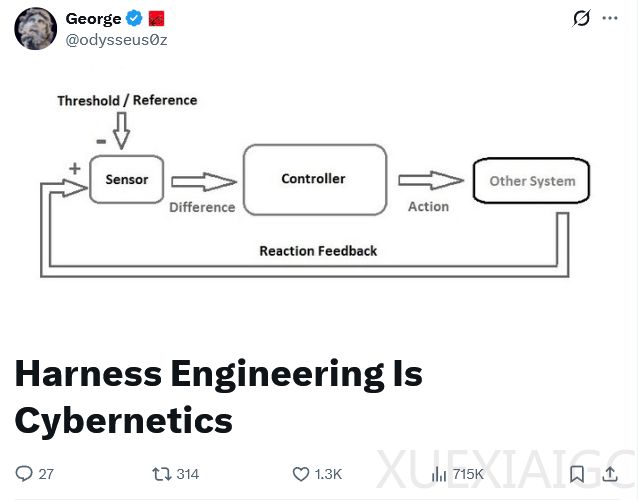
Anthropic近期深入探索了“Harness工程”在复杂AI任务中的应用价值,通过系统性框架提升模型在长周期、高复杂度任务中的可靠性和产出质量。其核心发现在于:AI在执行复杂任务时易出现“半途而废”现象,主要源于两大认知瓶颈——一是“上下文焦虑”,即模型因记忆负荷增加而草率收尾;二是缺乏客观的自我批评能力,导致对自身成果评价过于宽容,尤其在主观性较强的领域如界面设计中表现明显。为解决这些问题,Anthropic构建了以任务分解、上下文重置与角色分离为核心的支撑体系。
上下文重置机制被证明是缓解“上下文焦虑”的有效手段,它通过生成交接文档,使模型能获得全新起始状态,从而避免疲劳式收尾。 在评估环节上,研究者发现将生成与评审角色分立比训练生成器自我批判更为高效——让独立的评估器承担“挑刺”职责,既降低了对生成器能力的苛刻要求,又提供了更明确的改进方向。实验表明,评分标准的制定极大影响产出质量,当设计质量和原创性权重显著提高时,模型开始突破模板化输出,例如在荷兰艺术博物馆网站设计项目中,第10轮迭代出现了令人惊喜的3D空间沉浸式方案。
三智能体协同架构(规划器+生成器+评估器)成功映射软件开发全生命周期,其中“短跑合约”成为关键保障机制,确保每次功能开发前双方就成功标准达成一致。 实践检验显示,在复古游戏制作器项目中,采用Harness的三智能体方案相较单智能体方案大幅提升完成度:界面布局合理、交互逻辑完整、核心功能可用,尤其是游戏可玩性得到本质性突破。评估器日志揭示其主动导航页面、截图分析、逐项核验测试标准的能力,为迭代改进提供精细化依据。
面对Harness的开销压力问题,研究人员基于Opus 4.6模型的能力跃升进行精简重构,尝试移除部分组件以提升效率。结果表明,“是否启用评估器”应取决于任务复杂度与模型当前能力边界的匹配程度,而非一成不变地全量部署——在4.6模型下,生成器自主完成大量任务,仅在边界区域仍需评估器介入,实现性能与成本的动态平衡。
持续实践证明,随着大模型能力增强, Harness非但未被取代,反而拓展至更高层次的应用可能;AI工程师的核心挑战已从“如何控制模型”,转向“如何构想更有创意的组合模式”。 真正有效的Harness设计始终依托真实场景的实验记录,并伴随新模型发布同步进化,保持对“当前能力天花板”和“未来扩展空间”的精准判断与动态调整。
原文和模型
【原文链接】 阅读原文 [ 4338字 | 18分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★★★★★


相关文章


