从零开始手搓GPU,照着英伟达CUDA来,只用两个星期
文章摘要
【关 键 词】 芯片设计、并行计算、GPU架构、Verilog、OpenLane EDA
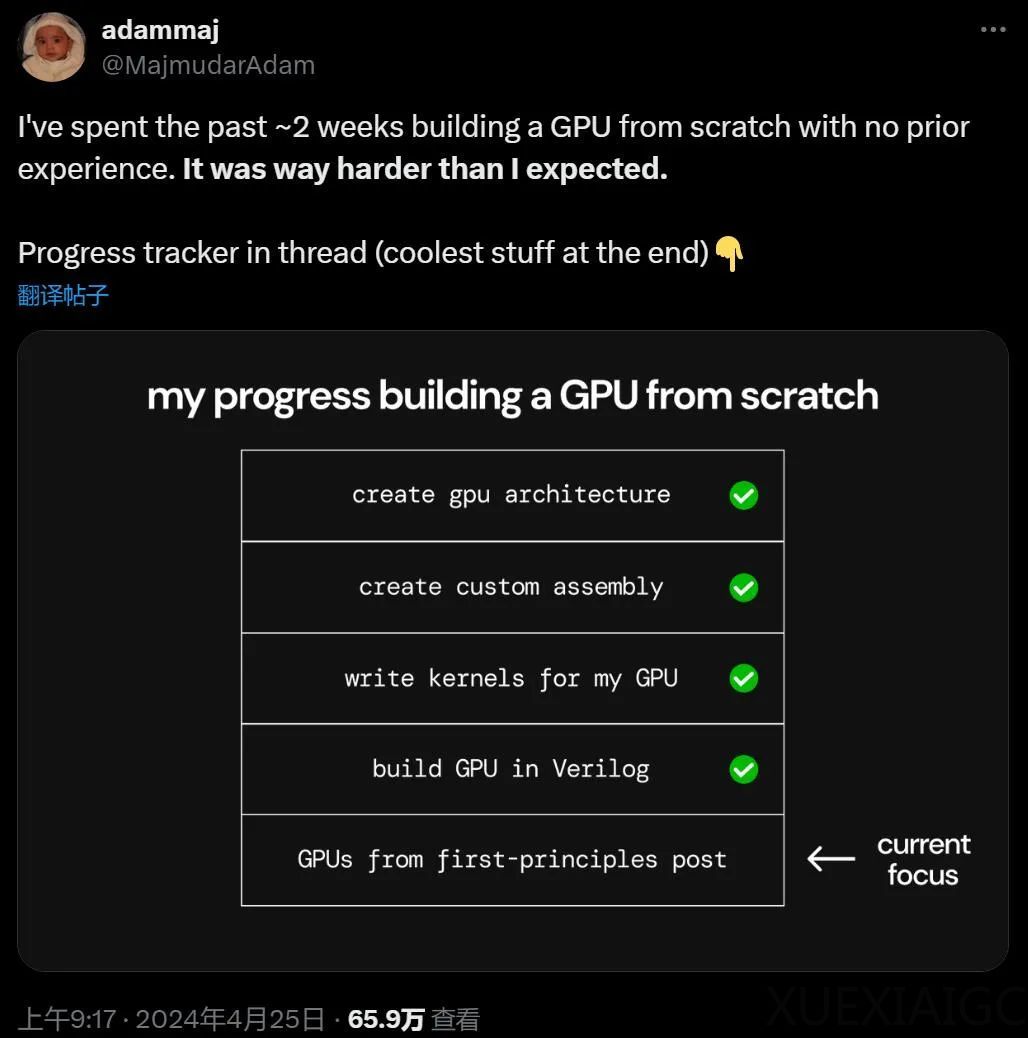
Adam Majmudar,一位美国web3开发公司的创始工程师,分享了他在两周内从零开始构建GPU的经历。他的项目在GitHub上公开,获得了5300个Star。Majmudar的GPU设计目前已在Verilog中布局,并通过OpenLane EDA软件验证。接下来,该GPU将通过Tiny Tapeout 7提交流片,预计在未来几个月内成为物理形态的芯片。
Majmudar在设计GPU之前,首先学习了英伟达的CUDA框架,理解了SIMD编程模式,并深入研究了GPU的核心元素,如全局内存、计算核心、分层缓存、内存控制器和程序调度。他还研究了计算核心中的主要单元,包括寄存器、本地/共享内存、加载存储单元(LSU)、计算单元、调度程序、获取器和解码器。
在设计自己的GPU架构时,Majmudar强调了并行化、内存访问和资源管理的重要性,并决定专注于通用并行计算(GPGPU)功能,以适应机器学习等更广泛的用例。他设计了一个简化的GPU架构,以便其他人可以更容易地理解GPU的核心概念。
Majmudar还为他的GPU设计了自己的指令集架构(ISA),并编写了一些简单的矩阵数学内核作为概念证明。他遇到了许多问题,包括如何处理全局内存的实现和计算核心内的调度问题。在George Hotz的建议和帮助下,他对设计进行了多次重写,最终实现了目标。
Majmudar的GPU设计通过OpenLane EDA实现,并采用Skywater 130nm工艺节点。尽管遇到了一些设计规则检查(DRC)失败的问题,但他最终完成了设计,并得到了3D可视化的GPU布局。
Majmudar表示,他在很短的时间内掌握了芯片架构和制造的基础知识,并完成了他的第一个完整芯片布局,即手搓CPU。他总结了手搓芯片的六个主要步骤:学习芯片架构和制造的基础知识,开始电子设计自动化,用Verilog创建电路,实施仿真和形式验证,以及使用OpenLane进行设计和优化。
在工程师圈子里,尝试手搓芯片并不少见,但大多数人尝试的是CPU。中国科学院大学的「一生一芯」计划是一个例子,该计划由本科生主导完成了一款64位RISC-V处理器SoC芯片设计并实现流片。随着开源芯片和敏捷设计等行业新趋势的发展,芯片设计门槛正在降低,未来可能会出现更多性能更强大的自造芯片实践。
原文和模型
【原文链接】 阅读原文 [ 2710字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 gpt-4
【摘要评分】 ★★★★★


相关文章


