DiT架构大一统:一个框架集成图像、视频、音频和3D生成,可编辑、能试玩
文章摘要
【关 键 词】 Diffusion Transformer、图像生成、多模态、跨模态生成、AI模型
本文报道了基于Diffusion Transformer(DiT)的新模型Flag-DiT,该模型由上海AI Lab、港中文和英伟达的研究者联合推出,旨在通过流(Flow-based)的大型扩散Transformers实现图像、视频、音频和3D对象的生成。Lumina-T2X系列模型包括具有70亿参数的Flag-DiT和130亿参数的多模态大语言模型SPHINX,后者能处理128K tokens。
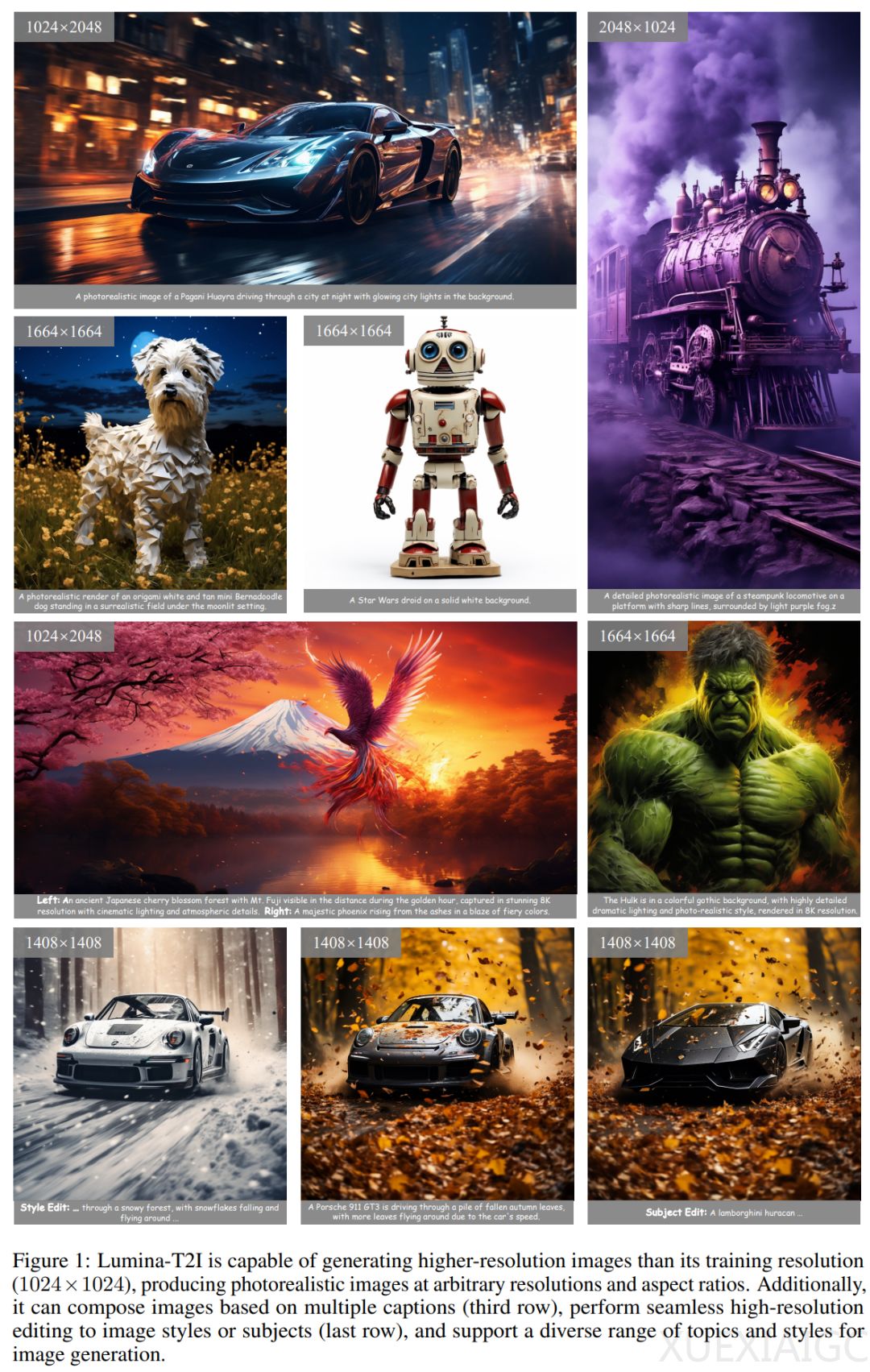
Lumina-T2X系列模型的基础文本到图像模型Lumina-T2I利用流匹配框架,在高分辨率真实图像文本对数据集上进行训练,以较少的计算资源取得高质量的结果。Lumina-T2I能生成任意分辨率和宽高比的图像,并实现分辨率外推、高分辨率编辑、构图生成和风格一致生成等高级功能。
Lumina-T2X系列模型通过独立训练视频-文本、多视图-文本和语音-文本对,增强了跨模态的生成能力。例如,Lumina-T2V能生成任何宽高比和时长的720p视频,缩小了与Sora模型的差距。
Flag-DiT作为Lumina-T2X框架的主干,具有稳定性、灵活性和可扩展性。稳定性通过替换LayerNorm为RMSNorm和引入键查询归一化(KQ-Norm)来增强。灵活性方面,通过用RoPE替换APE来注入相对位置信息,以适应任意分辨率和比例的样本生成。可扩展性则是通过扩大参数大小和训练样本来实现。
Lumina-T2X的训练过程包括四个组件:不同模态的逐帧编码,使用多种文本编码器进行文本编码,以及利用Flag-DiT和SPHINX模型。目前,Lumina-Next-T2I模型已推出,并可在gradio上试玩。
文章提供了论文地址、GitHub地址、模型下载地址和试用地址,供读者进一步了解和体验Lumina-T2X系列模型。
原文和模型
【原文链接】 阅读原文 [ 5257字 | 22分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章


