入围CVPR 2026最佳论文决选,ViT³用「测试时训练」突破Transformer复杂度瓶颈
文章摘要
【关 键 词】 视觉模型、测试训练、架构创新、多模态、高效推理
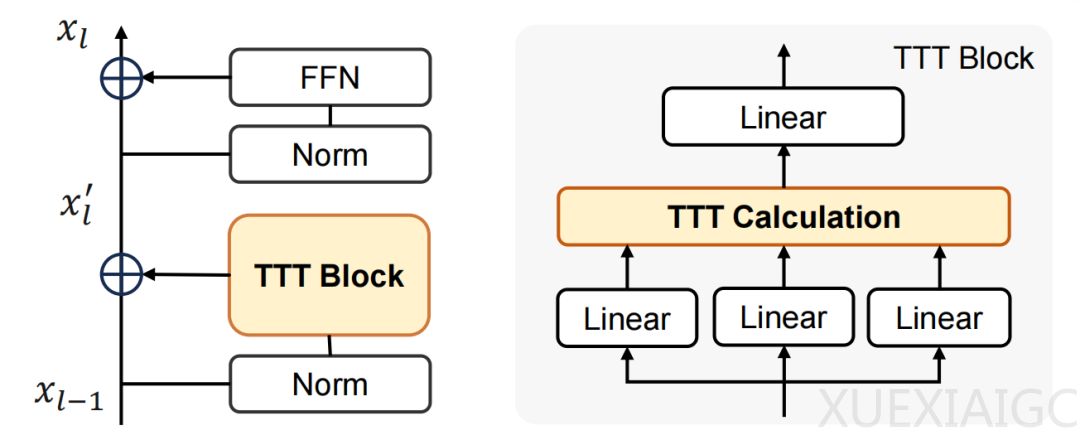
阿里巴巴与清华大学合作的研究提出了ViT³模型,旨在解决视觉Transformer在处理高分辨率图像和复杂多模态输入时计算与显存成本急剧增加的问题。该研究将测试时训练框架系统引入视觉领域,把上下文压缩转化为一次快速的在线学习过程。与依赖固定矩阵乘法的线性注意力机制不同,测试时训练在推理阶段将输入视为临时数据集,对小型内部网络进行短暂的自监督训练,从而在保持线性复杂度的同时提升信息压缩与表达能力。
研究系统梳理了视觉测试时训练的设计空间,并总结出六项核心实践原则。这些原则指出,内部训练的损失函数混合二阶导数不能为零,视觉任务更适合全批次单轮训练,且在稳定前提下较大的内部学习率效果更好。此外,增加内部模型容量能持续提升性能,而当前更深的内部模型面临优化困难,卷积结构则天然适合作为内部模型以整合全局与局部信息。
基于上述原则,研究团队构建了非层级架构的ViT³、层级设计的H-ViT³以及用于图像生成的DiT³。实验表明,这些模型在图像分类、目标检测、语义分割和图像生成等任务中展现出强大的表征与生成能力,超越了多种同级别的线性复杂度模型。在处理高分辨率图像时,ViT³的优势尤为显著,其推理速度达到传统模型的4.6倍,同时GPU显存消耗大幅降低了90.3%。
这项研究证明了通过架构创新可以在控制算力成本的前提下维持较强的建模能力。ViT³不仅为高分辨率多模态应用和端侧部署提供了极具扩展性的视觉底座,也印证了算力与性能并非互斥,更聪明的架构设计是突破现有计算瓶颈的有效途径。
原文和模型
【原文链接】 阅读原文 [ 4796字 | 20分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


