文章摘要
【关 键 词】 视频生成、视频编辑、多模态、扩散模型、开源框架
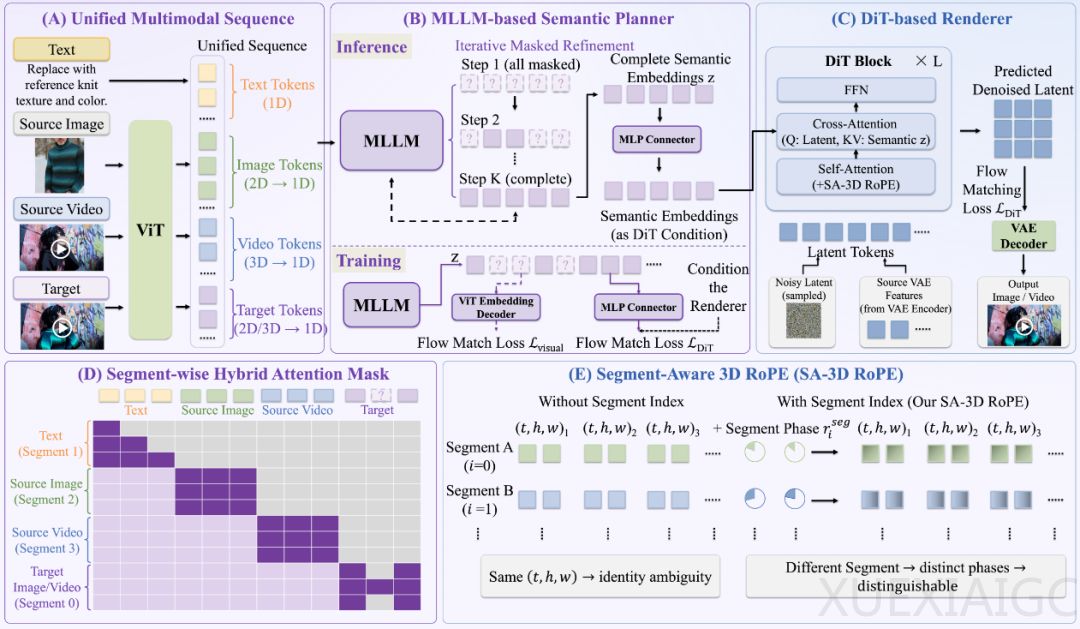
Bernini团队发布并开源了一款将多模态大模型与扩散模型深度融合的统一视频生成与编辑框架。该框架通过物理分工理念,让多模态大模型担任语义规划师,基于DiT架构的扩散模型担任像素渲染师,两者在视觉Transformer嵌入空间进行高效交互。这种设计使得两个模型能够独立完成主体预训练,仅需在最后阶段进行轻量级联合调优,从而大幅降低联合训练开销并保持各自优势。
为应对复杂视频编辑中的视觉歧义与逻辑难题,研究团队引入了多项创新机制。分段感知3D旋转位置编码通过为不同素材片段分配专属索引,彻底解耦了身份信息与纯粹的时空位置,从根源上杜绝了特征信息的错误泄漏。同时,模型采用两段式思维链推理机制,面对简单指令启动自我文本推理进行扩写,面对复杂因果编辑则启动自我视觉文本推理,先生成中间视觉状态再扩展至时间轴,显著增强了画面的物理逻辑底蕴。
在数据与系统优化方面,团队采用三阶段循序渐进的训练策略,并构建了包含数千万对视频与图像素材以及百万级微观动作数据的大规模全能语料库。通过对底层并行配置的重构以及引入两阶段模型蒸馏机制,模型不仅大幅降低了显存占用,还将序列吞吐极限提升了数倍,同时仅需极少运算步数即可呈现高质量画质。
在性能评测环节,研究团队手工打造了涵盖多个维度与细颗粒度子项的权威基准库。测试结果表明,该框架在维持视频一致性、指令遵循以及生成质量上展现出卓越性能,在多个权威视频编辑和生成榜单中取得顶尖成绩,整体表现全面超越多款闭源头部产品。这一成果标志着多模态大模型与扩散模型的结合在视频生成与编辑领域取得了重要突破。
原文和模型
【原文链接】 阅读原文 [ 2625字 | 11分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


