强化学习之父Richard Sutton给出一个简单思路,大幅增强所有RL算法
文章摘要
【关 键 词】 强化学习、奖励聚中、折现因子、性能提升、算法改进
阿尔伯塔大学教授Richard Sutton及其团队提出了一种名为“奖励聚中”(Reward Centering)的新型强化学习思想,旨在改进现有强化学习方法。该思想通过从奖励中减去实际观察到的奖励的平均值,使修改后的奖励以均值为中心,适用于几乎所有强化学习算法。这一理论基于有限马尔可夫决策过程(MDP),智能体的目标是最大化长期获得的平均奖励。通过估计每个状态的预期折扣奖励总和,团队发现,当折现因子γ接近1时,奖励聚中的好处更加明显。
奖励聚中的优势在于其能够通过折现价值函数的罗朗级数分解来揭示。这种分解表明,折现价值函数可以被分解成两部分,其中一部分是一个常数,并不依赖状态或动作,因此并不参与动作选取。这种分解有助于解决bandit问题,并在完整的强化学习问题中,与状态无关的偏移可能会相当大。
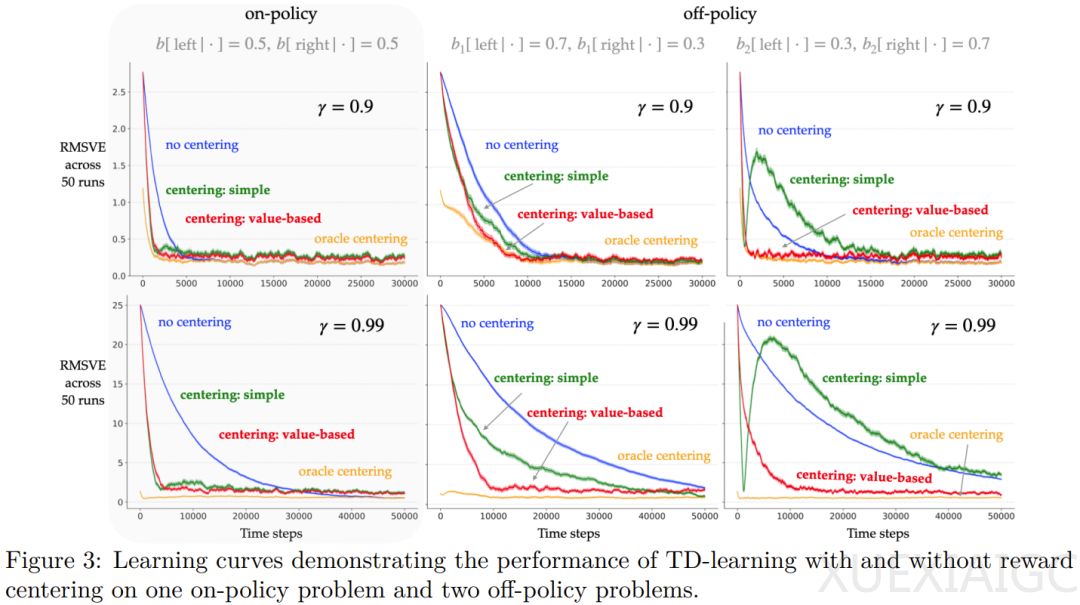
实验表明,奖励聚中能够提高Q学习算法的表格、线性和非线性变体在多种问题上的性能,尤其是当折现因子接近1时,学习率的提升更为显著。此外,该算法对问题奖励变化的稳健性也有所提升。团队还提出了简单奖励聚中以及基于价值的奖励聚中两种方法,其中基于价值的聚中在离策略问题上表现更佳。
总体而言,奖励聚中这一简单方法能够显著提升强化学习算法的性能,尤其是在折现因子较大时。这一发现为强化学习领域提供了新的研究方向和改进现有算法的可能性。
原文和模型
【原文链接】 阅读原文 [ 2325字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

