百度开源无限OCR,跑通长程解析,核心作者YY疑是来自DeepSeek
文章摘要
【关 键 词】 文字识别、长程解析、百度开源、滑动窗口、解码优化
百度近期开源了Unlimited OCR模型,该模型在标准最大上下文长度32K的条件下,首次实现了一次前向推理直接完成数十页长文档的端到端解析,打破了传统逐页处理的局限。在主流基准OmniDocBench v1.5测试中,Unlimited OCR以93.23%的总分取得端到端最优表现,显著超越了DeepSeek OCR。
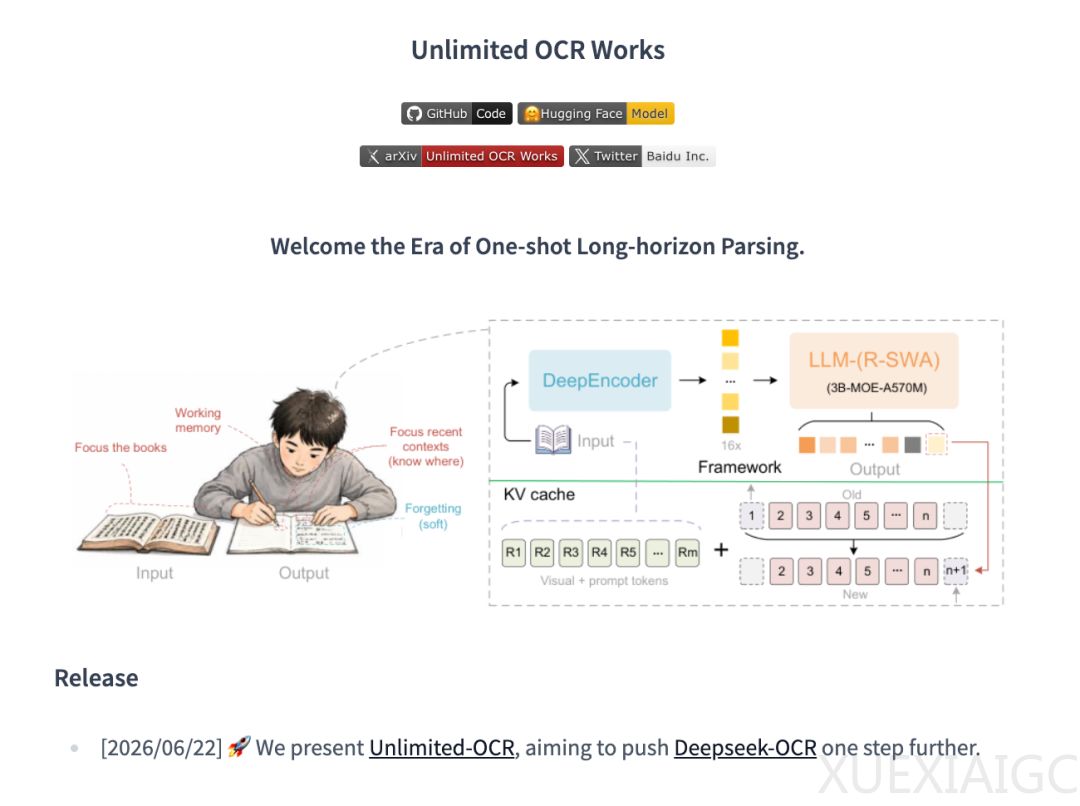
该模型直接构建于DeepSeek OCR的基础之上,两者分别聚焦于技术路线的不同环节。DeepSeek OCR通过DeepEncoder实现了输入侧高分辨率文档的极致视觉token压缩,而Unlimited OCR则致力于解决输出侧解码阶段KV Cache不断膨胀导致的显存占用高和生成速度慢的问题。
为突破长程解码瓶颈,研发团队受人类抄书时软遗忘认知状态的启发,提出了参考滑动窗口注意力机制(R-SWA)。该机制将模型关注的信息划分为始终可见的参考信息与仅保留最近128个token的固定容量输出缓冲区。这种设计使得模型在长文本生成过程中,能够保持恒定的KV Cache,从而确保计算开销和显存占用不会随输出长度增加而膨胀。
实验结果表明,Unlimited OCR不仅在复杂版式文档中保持了高准确率,还在长程解析任务中展现出卓越性能。在40页以上的长文档场景中,模型依然维持较低的编辑距离和高文本多样性。随着输出序列长度的增加,R-SWA机制使模型的推理速度保持恒定,彻底解决了传统多头注意力机制在长序列下速度衰减的问题。此外,Unlimited OCR在技术架构与报告风格上与DeepSeek OCR高度契合,显示出两项研究在技术路线上的连贯性与递进关系。
原文和模型
【原文链接】 阅读原文 [ 3782字 | 16分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


