文章摘要
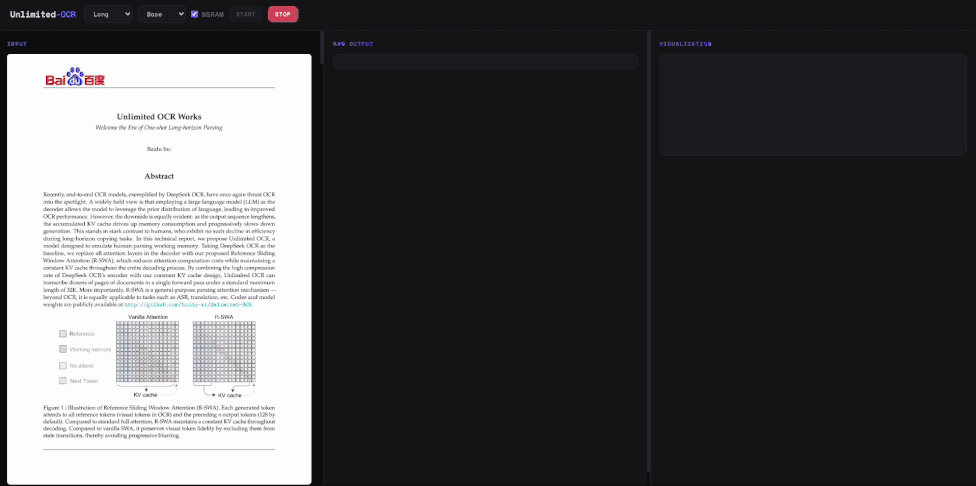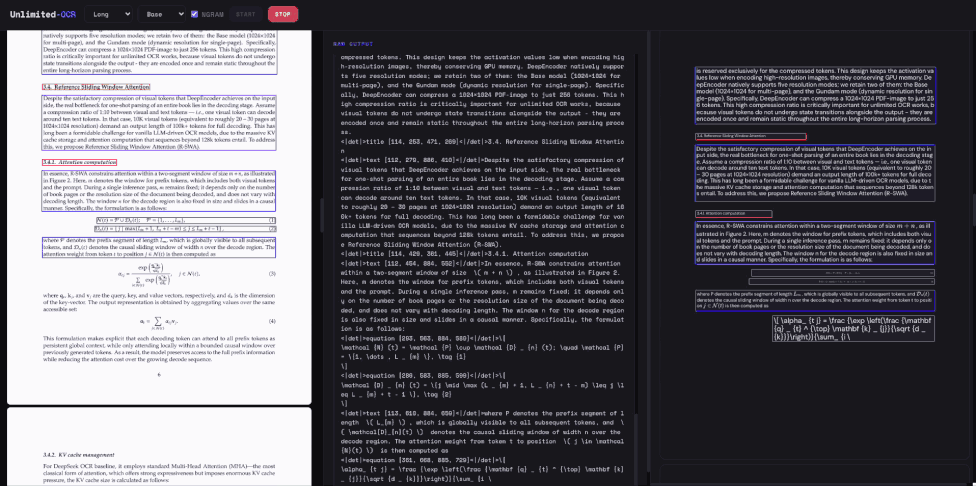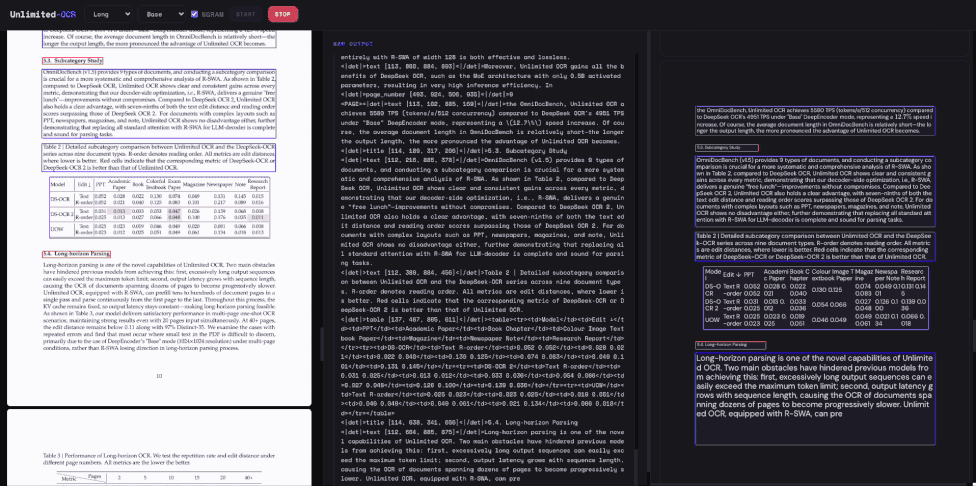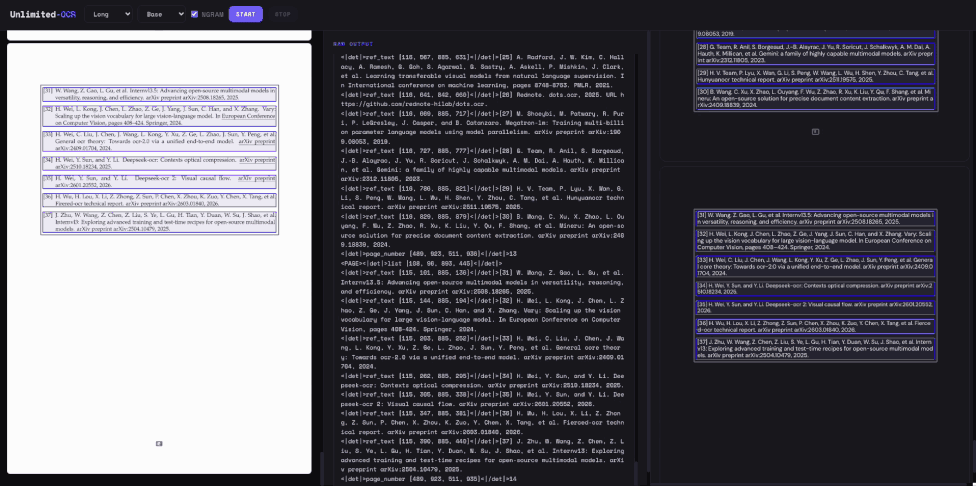
百度推出的Unlimited-OCR模型成功将端到端光学字符识别技术提升至新高度,有效解决了长文档解析中的工作记忆难题。当前主流大语言模型在处理长序列时面临KV cache线性增长导致的显存和速度瓶颈,传统逐页处理的工程方案割裂了长文档的连续性。Unlimited-OCR的核心创新在于引入了参考滑动窗口注意力机制,将解码器的KV cache从线性增长压缩为常数级别。该机制使模型在生成每个词元时,能够关注全部参考词元以及最近输出的固定数量词元,同时避免视觉特征在状态更新中模糊,从而实现了类似人类边抄边忘的软遗忘工作记忆。
在架构与训练方面,Unlimited-OCR沿用了DeepEncoder进行视觉编码,采用混合专家模型,并将所有注意力层替换为全新机制。通过在两百万份单页与多页文档数据上进行续训,该模型在计算成本和显存占用上实现了双重稳定。在OmniDocBench基准测试中,Unlimited-OCR取得了端到端最优性能,在文本、公式、表格等多项指标上均显著优于现有模型。此外,其推理速度也得到大幅提升,理论每秒生成词元数在长文本输出场景下优势更为明显,充分验证了全新注意力机制在解析类任务上的有效性。
在实际长文档测试中,该模型能够单次前向转录数十页文档,即使在四十页以上的超长文档中依然保持较高的识别准确率,证明了新机制在长程解析中不会迷失方向。这种参考滑动窗口注意力不仅局限于光学字符识别,作为一种通用的解码方案,它同样适用于自动语音识别、机器翻译等任何包含参考词元的长输出任务。尽管目前在极长上下文预填充方面仍存在一定局限,但相关代码与模型权重的开源为后续扩展上下文长度及探索更复杂的长程解析任务奠定了坚实的技术基础。
原文和模型
【原文链接】 阅读原文 [ 1866字 | 8分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★☆☆


相关文章


