视频AI卷向5分钟:全量开源,一次生成,正式告别「盲盒抽卡」
文章摘要
【关 键 词】 长视频、视频生成、音画一致、京东开源、人机协作
当前AI视频生成技术在处理分钟级长视频时,常面临角色形象改变、声音不一致以及修改成本高昂等瓶颈,难以真正融入专业内容生产工作流。针对这一行业痛点,京东近期开源了长音视频生成框架JoyAI-Echo,成功实现了长达五分钟的跨镜头音视频双重一致性。该框架不仅保证了角色面部特征和说话音色在长时序和复杂多视角下的统一,还打破了传统盲盒式生成的局限,支持通过自然语言指令进行局部修改与非线性剪辑。
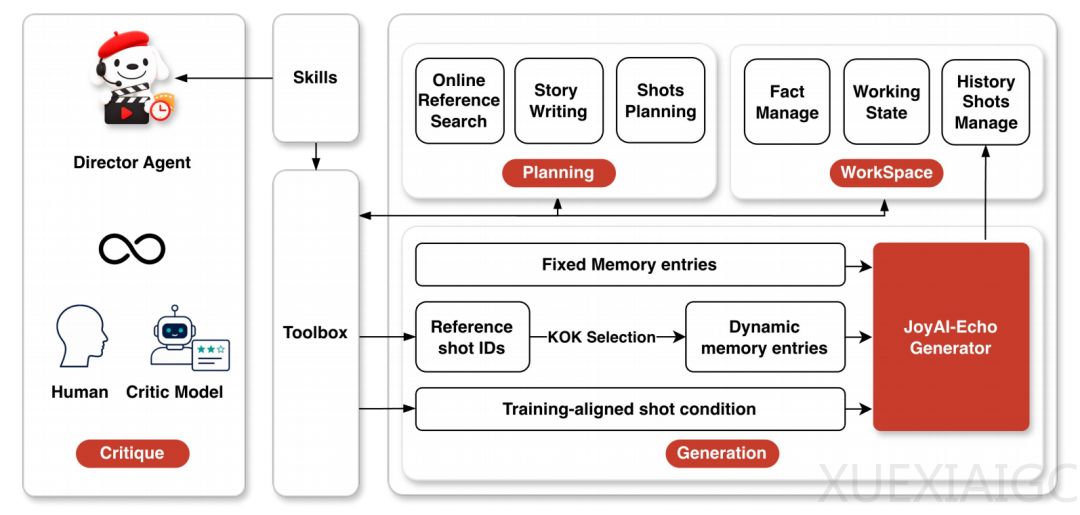
在技术创新方面,JoyAI-Echo构建了百万级身份向心型视频语料库,从数据源头解决了角色变脸问题。同时,模型采用了基于槽位配对的音视频记忆交互机制,将角色的面部与声音进行直接绑定,有效防止了跨事件中的人脸与声音混淆。此外,研究团队设计了一套由浅入深的后训练体系,通过长上下文损失重定向、多分辨率渐进式微调、跨模态对齐强化以及分布匹配蒸馏等技术,显著提升了口型同步精度、画面质感与推理速度。
为了让技术真正落地于工业级生产,该框架引入了智能导演智能体与联合单步超分架构。智能导演智能体能够将用户的模糊需求转化为结构化剧本,并支持针对单一镜头的局部重绘与记忆更新,使整条长视频无需重新生成即可修改。联合单步超分架构则在维持极低延迟的同时,直接输出最高2K分辨率的高清视频与精细化音频。
评测结果显示,JoyAI-Echo在视听一致性、台词准确率及成片偏好等指标上均表现优异。这一开源框架的出现,标志着AI长视频生成从演示层面迈向了好用的工业级生产工具阶段,重塑了创作者与AI之间的人机动态协作范式。代码与权重的全量开放,不仅为垂直行业的二次开发提供了基础,也为整个视频生成产业的基础设施建设提供了重要支撑,推动了AI长视频时代的实质性发展。
原文和模型
【原文链接】 阅读原文 [ 3531字 | 15分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


