文章摘要
【关 键 词】 强化学习、图形界面、轨迹重构、奖励塑形、信用分配
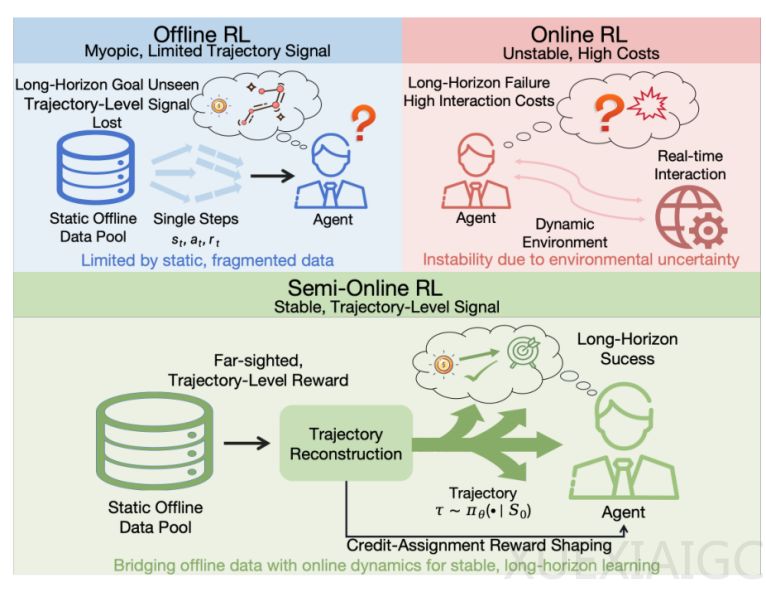
针对训练图形用户界面智能体时在线强化学习交互成本高易崩溃、离线强化学习时序短视且误差累积的困境,相关研究提出了一种半在线强化学习框架。该框架旨在保留离线训练稳定性的同时,将全局轨迹信号回填至离线学习过程中,以解决长程任务中的信用分配难题。
该框架的核心方法包含离线轨迹重构与轨迹感知奖励塑形两个关键组件。在离线轨迹重构阶段,通过对同一任务的每一步并行采样多条候选轨迹并首尾相接,结合严格的逐步有效性核验与截断机制,将有限的静态数据扩展为多样化的伪在线探索数据。在奖励塑形阶段,系统通过失败点检测与前缀信用分配,结合原子动作细粒度打分与目标对齐的动态惩罚机制,将整条轨迹的执行质量回溯性拆解为稠密且与全局目标对齐的步级奖励。
实验结果表明,该半在线强化学习机制能够彻底规避长程训练中的策略崩溃,并在零环境交互的前提下取得优异表现。在多个主流基准测试中,仅使用约10%数据预算的训练成果,即可达到甚至超越依赖大规模在线交互或海量数据的强基线模型,展现出极高的样本效率与训练稳定性。对训练过程的分析揭示,长程图形用户界面任务的成功关键不在于零失误,而在于智能体能否具备连续纠错的能力,即从次优状态中迅速恢复并回到有效决策路径。
尽管该方法在提升训练稳定性和样本效率方面成效显著,但其半在线机制仍受限于离线数据的分布覆盖面,无法处理分布之外的全新状态。此外,当前的有效性校验高度依赖真值标签,且评测场景主要集中在移动端操作系统。未来的研究方向将致力于引入学习型验证器以适配弱标注数据,并将该奖励塑形机制推广至桌面操作系统与网页浏览器等更为复杂的跨平台环境。
原文和模型
【原文链接】 阅读原文 [ 2420字 | 10分钟 ]
【原文作者】 量子位
【摘要模型】 qwen3.7-plus
【摘要评分】 ★★★★★


相关文章


