阿里RTPurboV2:原生Transformer再次崛起,百步训练实现10倍稀疏注意
文章摘要
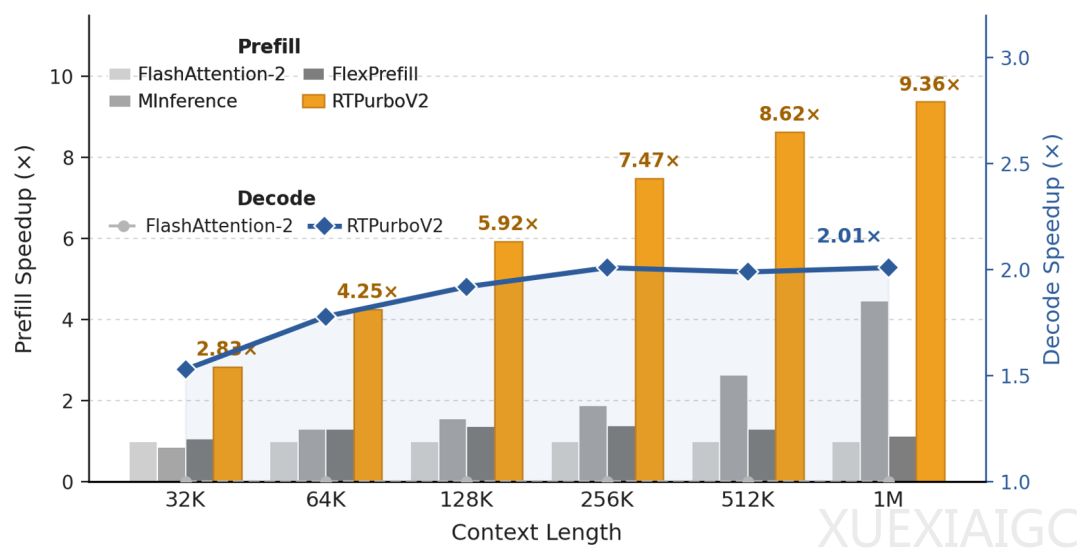
随着大模型应用中长序列需求的增加,传统全注意力机制因计算复杂度高而成为性能瓶颈。阿里团队推出了第二代注意力压缩技术,旨在彻底解决全注意力机制在超长序列下的推理瓶颈。该技术通过结合逐头压缩、低秩投影压缩以及聚类技术,在保留大部分滑动窗口注意力的基础上,对剩余的全注意力部分实现了极高的计算压缩。
研究表明,全注意力模型在预训练中已自发形成高度稀疏的结构。约85%的流式注意力头天然适配滑动窗口机制,而真正需要优化的是负责长距离信息召回的15%召回头。针对召回头,研究发现长程检索主要由旋转位置编码的低维子空间主导,高频分量会引入距离干扰。因此,通过低秩投影保留低频语义分量并过滤高频噪声,可大幅压缩特征维度。同时,低秩投影改善了向量在语义空间的分布质量,使得基于高质量特征的自适应聚类成为可能,从而构建出粗粒度匹配与细粒度计算相结合的两级漏斗式流程,将整体计算复杂度显著降低。
在注意力分数筛选方面,动态top-p策略被证明显著优于传统的固定top-k策略,能够根据不同查询的需求自动调整上下文覆盖范围,并结合无排序解码核将内存开销降至最低。为使模型适配这种稀疏化架构,仅需约600步的两阶段微调训练即可完成从隐式到显式的稀疏化转化,训练成本极低。
在多项长文本和复杂逻辑基准测试中,该压缩技术展现出了卓越的精度与加速效果。实验结果证实,该方案在大幅降低计算开销的同时,几乎无损地保留了模型的长程检索、基础理解与复杂推理能力。这一成果揭示了原生全注意力模型自身蕴含着巨大的效率提升空间,通过极低成本释放其内生稀疏性,无需替换底层架构即可达到前沿的压缩效率,证明了传统架构在长序列处理中依然具有强大的生命力。
原文和模型
【原文链接】 阅读原文 [ 2855字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


