文章摘要
【关 键 词】 模型推理、长上下文、键值缓存、预算分配、组合优化
随着人工智能应用中模型单次处理的上下文长度不断增加,键值缓存的内存占用随序列长度线性增长,成为制约推理效率和吞吐能力的瓶颈。当前主流的缓存压缩方案通常基于注意力分数分配预算,但这容易忽略不同注意力头在长期语义信息保留能力上的差异,导致缓存预算与长程信息价值错配。针对这一难题,百度百舸团队联合复旦大学提出了长程效用键值缓存框架,将头级缓存预算分配建模为面向长程边际效用的全局组合优化问题。
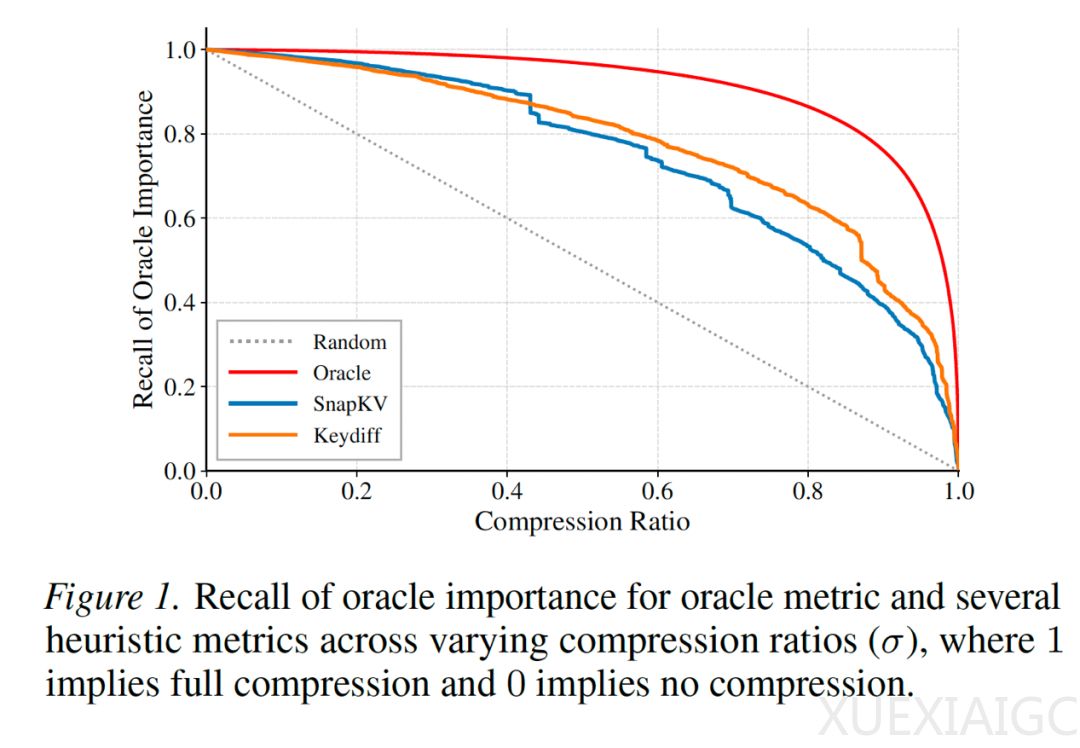
该框架的核心思路包含三个关键步骤。首先,研究团队定义了真实重要性指标,通过前瞻未来解码窗口计算每个令牌的最大潜在贡献,从而严格量化现有启发式指标与真实重要性之间的最优性差距。其次,为解决跨头预算分配这一非凸离散优化难题,团队引入凸包松弛技术,将复杂的组合优化问题转化为边际收益严格递减的平滑函数,并利用全局贪心算法快速逼近最优解,实现长程语义保留收益的最大化。最后,在工程落地方面,团队利用不同注意力头压缩率比例的结构稳定性,设计了数据驱动的离线画像协议,将复杂的在线计算转化为静态查表操作,实现了零开销部署,并且能够即插即用适配多种底层压缩指标。
在实验评估中,该框架展现了卓越的效率与精度权衡能力。在80%的缓存压缩率下,该框架在长文本评测基准上的相对性能损失仅为0.52%,达到了新的最优水平。在多个大语言模型上的测试表明,该方案有效最小化了总体逐出损失,显著提升了平均准确率,恢复了压缩模型与全量缓存上界之间的大部分性能差距。特别是在极端检索任务中,该方法在保留稀疏但关键信息方面展现出强大的鲁棒性,大幅超越了传统的均匀压缩和其他预算分配方案。相关研究成果已被国际机器学习顶会录用。
原文和模型
【原文链接】 阅读原文 [ 1758字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★☆☆


相关文章


