LoRA、完全微调到底有何不同?MIT 21页论文讲明白了
文章摘要
【关 键 词】 微调方法、LoRA、参数更新、泛化能力、持续学习
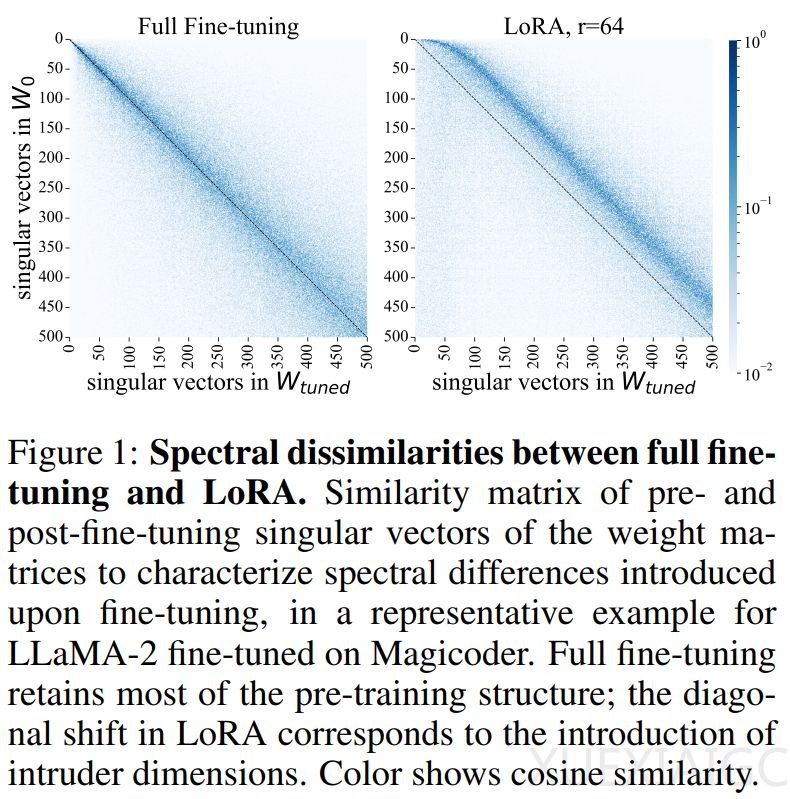
本研究旨在探讨完全微调和低秩自适应(LoRA)两种微调大型语言模型方法之间的差异。微调是将预训练的大型语言模型应用于特定下游任务的关键步骤,而LoRA方法在减少可训练参数数量的同时,被证明可以达到与完全微调模型相似的性能。MIT的研究者通过分析预训练模型权重矩阵的光谱特性,研究了不同微调方法如何改变模型,并发现完全微调和LoRA产生的权重矩阵奇异值分解结构有显著不同,且在面对超出适应任务分布的测试时显示出不同的泛化行为。
研究发现,LoRA训练的权重矩阵中出现了称为“侵入维度”的新的高秩奇异向量,而在完全微调中则不会出现。这表明,即使在微调分布上表现相同,使用LoRA和完全微调更新的模型访问参数空间的不同部分。LoRA和完全微调在结构上产生不同的参数更新,这种差异由侵入维度的存在产生。这些侵入维度是奇异向量,具有较大的奇异值,并且与预训练权重矩阵中的奇异向量近似正交。相比之下,完全微调模型在光谱上与预训练模型保持相似,不包含侵入维度。
从行为上看,与完全微调相比,具有侵入维度的LoRA微调模型会忘记更多的预训练分布,并且表现出较差的稳健连续学习能力。即使在目标任务上低秩LoRA表现良好,但更高秩的参数化可能仍然是可取的。低秩LoRA(r ≤ 8)适合下游任务分布,完全微调和高秩LoRA(r = 64)让模型泛化能力更强、自适应能力更加鲁棒。然而,为了利用更高的秩,LoRA更新模型必须是秩稳定的。
在较低秩下,LoRA在持续学习过程中的适应能力较差,会忘记更多之前的任务。研究在多个任务上按顺序训练RoBERTa,并测量学习新任务时性能的变化程度。结果表明,虽然LoRA最初与完全微调的性能相当,但较小的LoRA秩在持续学习过程中始终表现出更大的性能下降。随着LoRA秩的提高,这种遗忘行为减少,并且更接近于完全微调。对于微调到等效测试精度的LoRA模型,可以看到一条U形曲线,该曲线标识了适合下游任务的最佳等级,同时最小程度的忘记了预训练分布。
原文和模型
【原文链接】 阅读原文 [ 2015字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章


