文章摘要
【关 键 词】 多模态智能、持续学习、双流设计、经验技能、知识外化
人类从经验与技能双重维度持续进化,XSKILL据此设计双流学习机制,使AI具备类人记忆与策略复用能力。技能以Markdown文档形式存储于技能库,提供任务级工作流与工具模板;经验则以JSON格式保存于经验库,记录具体动作决策的触发条件、推荐行为及语义向量,形成动作级洞察支撑策略选择。这种分离设计既保障执行稳健性,又增强决策灵活性——当用户要求识别倒置图片中的吉祥物原型时,具备XSKILL的智能体可先调用图像过暗或颠倒时的处理经验,再链接旋转与裁剪工具模板生成有效计划,相较未集成该系统的同类表现明显更优。
系统采用积累—推理双阶段流程,确保知识提炼质量与任务适配效率。积累阶段对多路径推理轨迹进行视觉接地摘要,保留图像状态与动作选择之间的因果联系,并通过跨轨迹批判识别成功与失败间的关键差异,生成结构化经验更新指令;技能模块则从中抽象出通用工作流与代码模式,使用变量占位符增强跨任务兼容性。在推理阶段,通过任务分解检索与动态注入机制,智能体能依据当前上下文精准调用匹配的经验与技能片段,并将其整合为任务相关的工作流,同时记录实际使用情况反馈至积累阶段以迭代优化知识库。
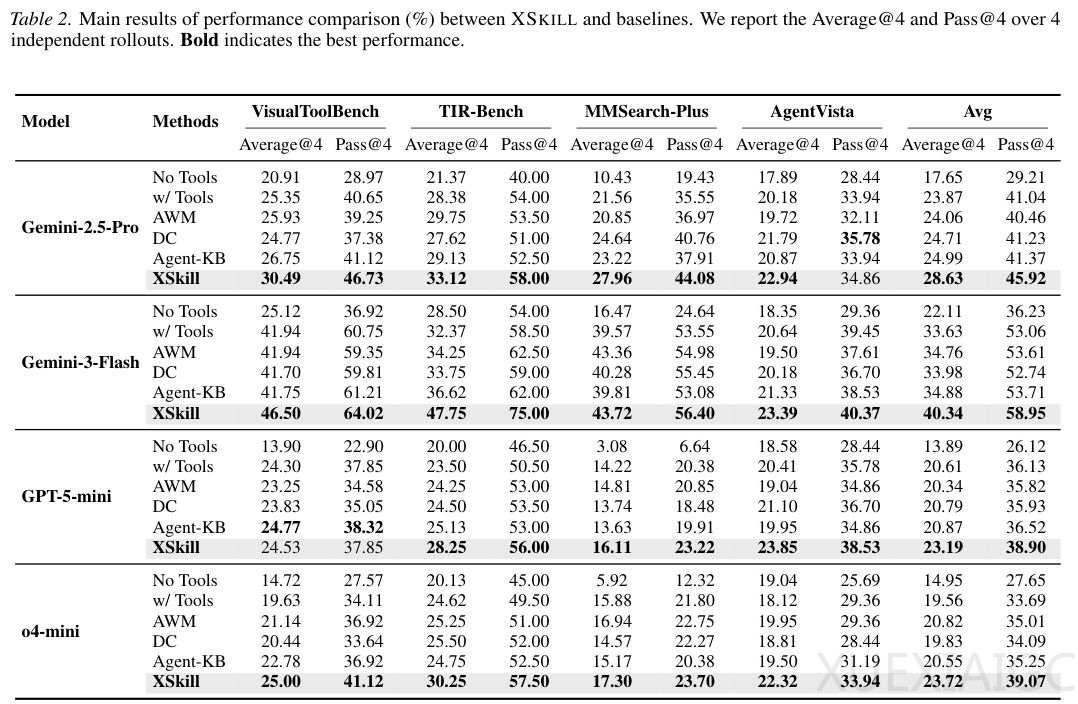
实证测试证明XSKILL在五个主流基准上全面超越现有基线模型,平均成功率提升达2.58–6.71个百分点,且迁移性能优异。其在TIR-Bench基准上以47.75%的成功率超越最强对比基线Agent-KB 11.13个百分点;GPT-5-mini和o4-mini在使用Gemini-3-Flash所积累知识后亦获得2.58–4.16百分点增长,体现知识结构在不同模型架构间的高度可迁移性。消融实验显示,技能与经验缺失分别导致3.85与3.04个百分点性能下降,说明两者缺一不可;其中技能主要降低执行错误,经验则调整工具选择策略,如在VisualToolBench中提升代码解释器使用率至76.97%,强化了上下文感知的工具编排能力。
知识层级整合机制与动态任务适配是其实现泛化与鲁棒性的关键所在。知识库通过余弦相似度比对实现经验合并、技能精炼,并避免冗余细节留存;推理时经验重写器按当前任务需求改写条件与动作,技能适配器同步裁剪非相关章节并注入非规范参考提示。随着推理次数增加,轨迹多样性提升促使跨轨迹批判更高效捕捉共性模式,从而进一步增强技能与经验的泛化效果。零样本迁移实验也证实,其基于层级整合所提取的知识在新领域仍保持稳定领先优势,比Agent-KB平均高出2–3个百分点。
XSKILL标志着AI智能体正从无状态系统迈向具备自主演进能力的持续学习范式。通过将经验与技能分离为可审计、可编辑、可删减的外化知识,它提升了决策过程的透明度与可控性,也为后续人工监督与安全治理奠定了基础。研究团队指出,尽管具备强大扩展性,仍需人类定期干预知识库偏见检测、制定跨模型访问规范,以防范潜在风险。最终结论明确:无需更新模型权重,仅靠挖掘过往轨迹中的智慧,AI同样能够实现越用越聪明的演化目标。
原文和模型
【原文链接】 阅读原文 [ 3135字 | 13分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★★★★★


相关文章


