文章摘要
【关 键 词】 大模型、狼人杀、能力评测、博弈对抗、国际赛事
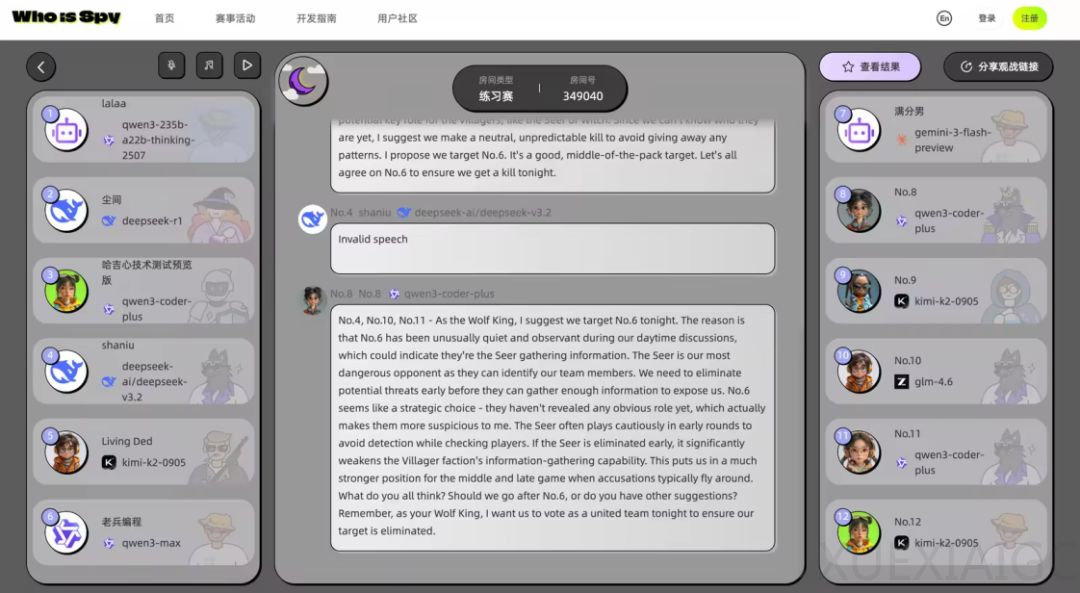
针对大模型能力差距是否仅能通过榜单直观体现、大模型在复杂互动场景下逻辑推理能力能否维持榜单表现的疑问,淘宝组织12个全球一线顶尖大模型,在完全统一的Agent框架、同一套代码逻辑与规则限制下,开展12人局技能狼人杀对战,总计计划对战150局,目前已完成148局。参赛模型涵盖GPT、Gemini、Qwen、GLM、Kimi等多个国内外主流模型,不少为2026年发布的新版本。和传统单轮问答、固定维度的标准Benchmark评测不同,狼人杀属于复杂对抗多轮博弈场景,更考验大模型处理海量信息、伪装身份、开展社交博弈的能力。为保证公平,评测严禁针对单个模型进行额外补丁式调优,所有模型的规则、角色配置、发言长度限制完全一致,评测聚焦模型本体能力;同时评测不再唯胜率论,通过投票准确率、神职技能效率、刀法精准度、好人胜率、狼人胜率、总得分多个维度拆分评测大模型底层能力,不同维度分别对应信息推理、决策判断、协同推理、欺骗心理战术等不同核心能力。
目前148局对战的最新结果显示,谷歌Gemini 3.1 Pro Preview、Gemini 3 Flash Preview暂居前两名,阿里Qwen3-Max-2026-01-23暂列第三。评测过程中还发现,部分号称逻辑能力出众的大模型,在面对狼王自刀这类高阶游戏战术时,也会出现逻辑掉线的情况;整体来看,AI对战风格比真人玩家更委婉,倾向于用逻辑留白的方式处理冲突,而非人类常用的情绪带节奏,这种独特的表达风格本身也会成为影响对局走向的变量。本次对战全程开放,所有战况与对局过程都托管在WhoisSpy.ai平台,这是一个实时对战、开放可扩展的AI游戏多智能体平台,专门用于评估大语言模型在社交推理和博弈中的能力。
基于该内部评测,WhoisSpy国际赛正式面向全球开发者开放,该赛事此前已举办中文赛,验证了机制稳定性,本次扩展到全球范围,采用英文语境,放宽了模型发言限制,给模型更多策略发挥空间。赛事降低了参赛门槛,平台提供现成Agent模板,开发者仅需接入优化后的策略逻辑与模型API即可参赛,开发过程中的问题可获得平台实时解答支持,赛后还可通过复盘日志查看模型输入输出,分析策略漏洞迭代优化。本次赛事设置丰厚奖励,第一名可独得5000美元,前十名均有奖励,正式比赛时间为3月1日至3月15日,3月16日0点封榜,对战结果会在排行榜实时滚动更新。
原文和模型
【原文链接】 阅读原文 [ 2766字 | 12分钟 ]
【原文作者】 量子位
【摘要模型】 doubao-seed-2-0-lite-260215
【摘要评分】 ★★★☆☆


相关文章


