文章摘要
【关 键 词】 AI图像编辑、多模态指令、数据生成、模型训练、性能评估
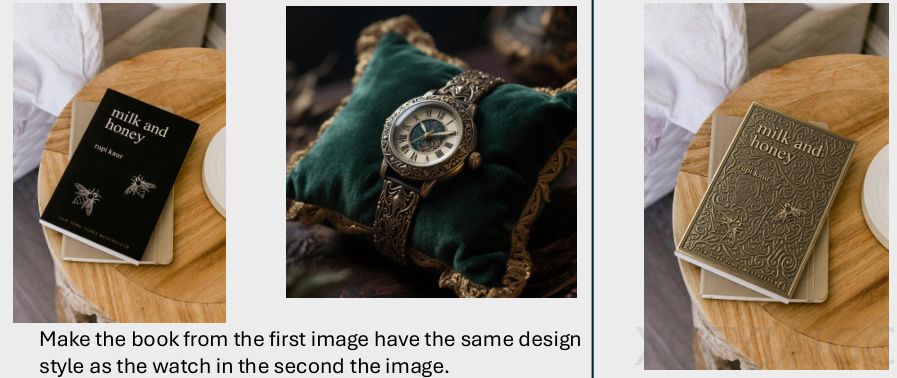
香港中文大学、香港科技大学、香港大学与字节跳动联合研发的DreamOmni2系统,标志着AI图像编辑与生成领域的重要突破。该系统通过创新的三阶段数据生成流程和模型架构设计,实现了对文本+图片多模态指令的精准理解与执行,显著提升了处理抽象概念(如风格、材质、光照)的能力。
数据构建是核心挑战之一。传统方法依赖分割模型抠图,难以捕捉抽象属性。DreamOmni2首创的三阶段解决方案:第一阶段训练特征混合提取模型,在不降低分辨率的前提下精准分离物体或属性;第二阶段通过T2I模型和指令编辑模型生成带标注的编辑数据;第三阶段扩展为多参考图生成任务数据。这套流程为模型提供了高质量”教材”,解决了多模态指令训练的数据瓶颈。
模型架构上采用两大关键技术:索引编码与位置编码偏移方案确保多图输入的精准对应,避免内容混淆;VLM与生成模型联合训练则通过”指令翻译”机制,将用户随意表述转化为结构化操作。特别值得注意的是,系统采用LoRA轻量化微调,既新增多模态处理能力,又完整保留基础模型的原有功能。
评测结果显示显著优势。在多模态编辑任务中,DreamOmni2超越所有开源模型,接近商业顶级水平;在生成任务上与GPT-4o表现相当,优于Nano Banana。对比实验显示,商业模型常出现属性偏差或色彩异常,而DreamOmni2在抽象属性编辑和具体物体生成上均保持更高一致性。研究团队构建的DreamOmni2基准测试集,为该领域提供了更全面的评估标准。
这项研究通过系统性创新,使AI图像处理从单一指令执行进阶为真正理解创作意图的协作过程,为数字内容创作开辟了新范式。技术方案中数据构建与模型设计的协同优化思路,对多模态AI发展具有普遍参考价值。
原文和模型
【原文链接】 阅读原文 [ 2112字 | 9分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


