刚刚,谢赛宁团队放出第二代表征自编码器
文章摘要
【关 键 词】 图像生成、扩散模型、表征学习、视觉编码、训练加速
传统变分自编码器在图像生成任务中逐渐显现出效率瓶颈,其潜在空间主要记录像素级物理特征而缺乏高层语义,导致扩散模型必须从零重复学习基础视觉常识。针对初代表征自编码器存在的重建质量不足、引导机制不兼容与训练收敛缓慢等缺陷,研究团队推出全面改进的RAEv2框架,旨在将成熟的预训练视觉编码器深度整合至扩散模型的潜在空间中。该框架通过三项核心技术洞察,成功打破了传统生成模型对独立索引系统的依赖。
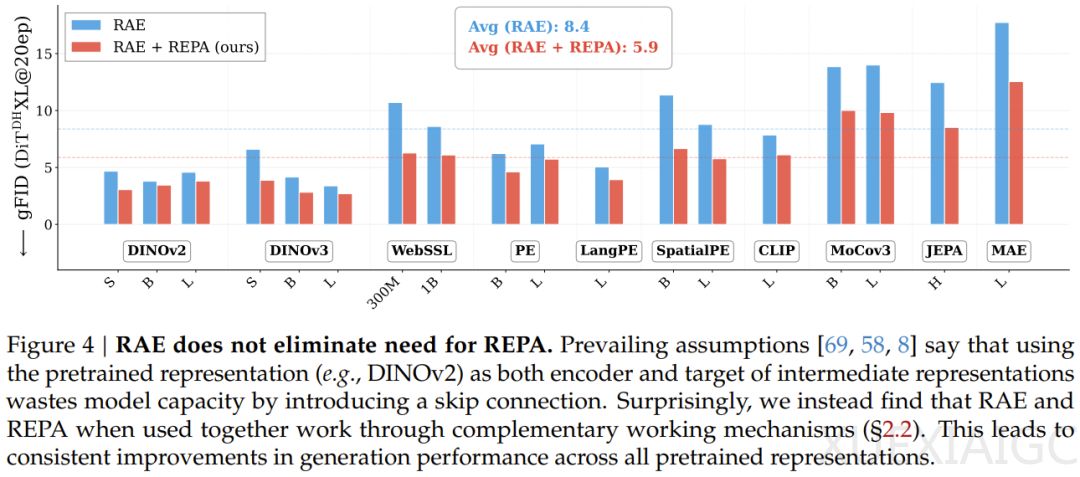
在架构设计上,新方法摒弃了仅提取编码器末层输出的局限,改为将网络末端多层特征进行直接叠加,从而完整保留推理过程中的细粒度信息,使重建误差大幅降低。大规模实验证实,表征自编码器与表征对齐机制并非冗余竞争,而是分别负责注入全局语义信息与强化空间拓扑结构的互补组件。同时,研究人员发现对齐头部天然具备弱模型特性,通过重构预测目标格式,可直接将其复用为分类器自由引导的基线,彻底免除了额外模型的训练开销与推理时的重复计算。
量化评估显示,技术整合后的系统在生成品质与迭代效率上取得显著突破。在维持极低算力消耗的前提下,新模型的训练收敛速度提升逾五倍,仅用少量训练周期即可达成超越同类基准的生成指标。其图像还原精度已能与在海量数据上训练的专用解码器相抗衡。跨任务测试进一步表明,该架构在文本驱动图像合成及视觉序列预测场景中均表现出一致的性能增益,验证了底层设计的高度泛化能力。
此项进展揭示了视觉判别模型与生成模型在底层表征层面走向统一的必然趋势。通过将生成过程直接迁移至富含语义的预训练空间,理解与创作两大范式得以共享同一套视觉表征语言。这一技术路径不仅优化了现有扩散模型的工程效能,更为未来构建能够直接在潜在空间进行逻辑推演的多模态通用系统提供了关键架构支撑。
原文和模型
【原文链接】 阅读原文 [ 2338字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.6-max-preview
【摘要评分】 ★★★★★


相关文章


