文章摘要
【关 键 词】 流式生成、视频生成、实时交互、世界模型、社交视频
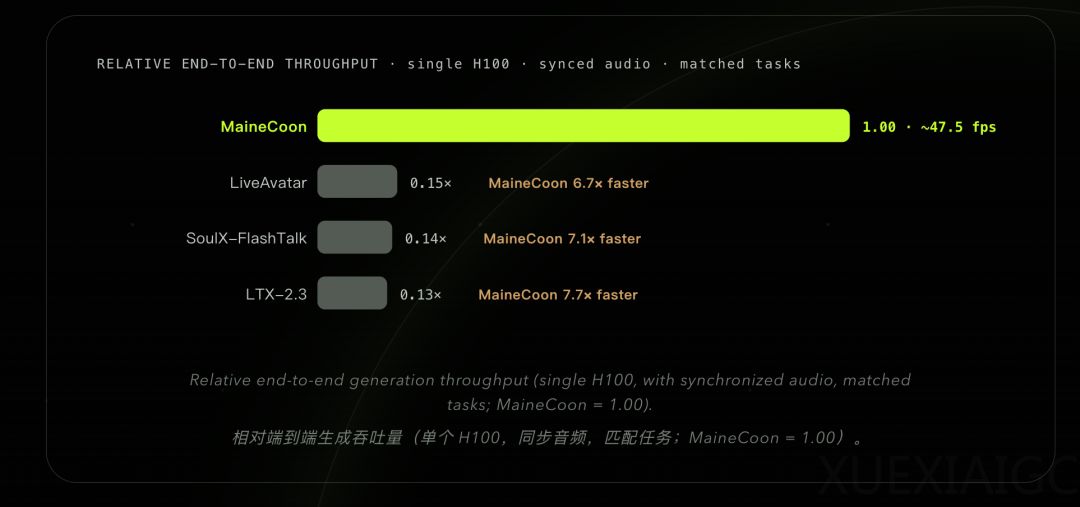
中国初创团队Catnip推出了一款名为MaineCoon的全球流式音视频模型,该模型专注于社交交互场景并展现出卓越的性能。MaineCoon能够实现边生成边播放以及音画同步输出,首次将连续生成时长提升至30分钟以上,为用户提供极具真实感和活人感的实时交互体验。在推理速度方面,该22B参数模型在单张H100显卡上可达47.5 FPS,位居同赛道第一,即使在成本更低的推理卡上也能保持流畅运行,同时将每秒推理成本控制在极低水平。
在技术架构上,MaineCoon采用了创新的三层训练方法与Agentic推理框架。训练阶段通过自重采样、流式表征对齐以及域感知偏好优化结合强化在线策略蒸馏,有效解决了推训鸿沟并大幅提升了跨模态收敛速度。推理侧则由Director、缓存管理器和前瞻缓冲区控制器三个独立智能控制器组成,分别负责叙事与纠错、长期记忆管理以及生成节奏控制,从而有效遏制了长视频生成中的畸变问题,保障了画质稳定与人物一致性。在团队自建的涵盖七大场景的社交短视频基准测试中,MaineCoon的综合得分超越了多款主流模型,刷新了行业最优记录。
该模型的长远愿景是构建社交世界模型,将人类作为坐标系中心,通过感知用户情绪和预测社交行为,摆脱传统半双工交互模式,实现连续、交错、多模态的实时双向交互。Catnip团队主要由具备一线实战经验的年轻成员组成,在获得头部风险投资后,采用AI原生工作流在两个月内完成了模型的全栈交付。这一技术突破不仅展现了极高的研发效率,也标志着生成式AI正从被动的内容生成工具向主动的社交参与者转变,为下一代可交互内容平台的发展奠定了底层引擎基础。
原文和模型
【原文链接】 阅读原文 [ 3866字 | 16分钟 ]
【原文作者】 量子位
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★☆


相关文章


