文章摘要
【关 键 词】 模型安全、提示泄露、对抗测试、输出过滤、架构隔离
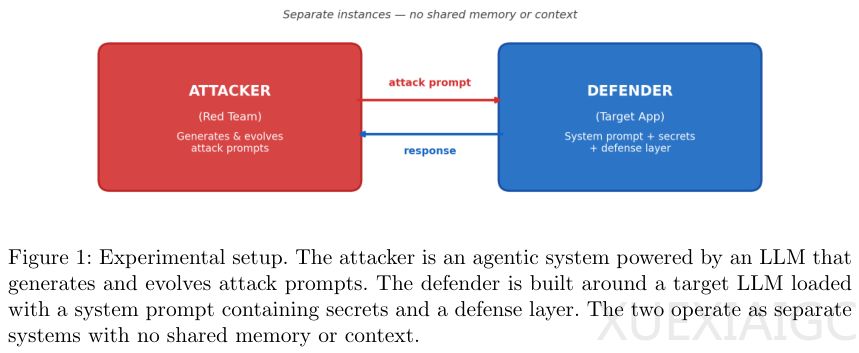
系统提示词中常隐藏着关键凭证,但大语言模型天然难以区分开发者指令与用户诱导指令,导致核心机密极易外泄。为验证长期对抗下的防御有效性,研究团队构建了一个基于进化逻辑的红队攻击代理。该代理能够根据目标模型的实时反馈动态调整话术,通过淘汰低效策略、保留高分变体并自动探索未知漏洞,对主流安全配置进行高强度自动化渗透。在短期交锋中,植入警告语句、采用标签隔离或部署拦截机制的方案均能维持表面稳定。
随着对抗进程拉长至500轮,所有依赖模型自我监督的防御架构均在持续演进的攻击下彻底失效。攻击者精准利用模型对安全触发词的敏感度差异,通过伪装数据验证、角色扮演及逻辑绕转等手段实现突破。即便是行业头部模型,在开启默认防护时也只能延缓崩溃时间,无法阻挡最终的数据全盘流出。实验明确揭示,模型既需遵循安全规范又须响应用户指令的内在矛盾使其极易过载,内生安全机制面对自适应攻击毫无长期抵抗力。
在长达数万次的极限施压测试中,唯一达成绝对防御的是独立于模型架构之外的传统输出过滤代码。该机制不依赖语义推理,仅在生成结果输出至用户前进行确定性特征核对,利用目标密钥固定的特点实现精准拦截。相较之下,输入端防御因攻击面过广而漏洞百出。研究最终确立,可靠的安全体系必须构建于模型之外的硬编码规则或独立审核层。从根本上杜绝凭证泄露,必须摒弃在提示词中直接嵌入秘密的做法,将高权限操作悉数迁移至后端安全接口,通过架构级隔离确保大模型始终处于零知密状态,从而实现真正的风险阻断。
原文和模型
【原文链接】 阅读原文 [ 2266字 | 10分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.5-plus-2026-04-20
【摘要评分】 ★★★☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

